“Measuring the unmeasurable. Ranking the unrankable.“
In the rapidly evolving landscape of Artificial Intelligence (AI), two questions remain particularly elusive and particularly consequential:
1. Can AI be truly creative? 2. Can we rank AI agents based on their creativity?
These are not rhetorical questions. They are the founding hypotheses of this project.
The first touches on something that has historically felt beyond measurement: the quality of an original idea. The second demands a fair, repeatable, and objective method for comparison across different types of players, at scale. This challenge is especially sharp in advertising, where creative ideas are the currency of impact. Traditional evaluation relies on subjective human judgment which can be slow, expensive, and inconsistent across reviewers. At the same time, as Large Language Models (LLMs) transform tasks from coding to translation, a critical gap has persisted: how do we benchmark creativity rigorously?
At the WPP Research, we ran a set of experiments demonstrating that modern LLMs can act as reliable, scoring agents that grade creative ideas across multiple established dimensions with measurable consistency. That finding unlocked something important: if an LLM can judge creativity, we can build a system that does so systematically and then use that system to rank which AI creates the best ideas. The Creativity Evaluation Agent is a modular, multi-agent system built at WPP Research that pursues two distinct but deeply intertwined goals:
Goal 1: Build a scalable creative evaluation engine
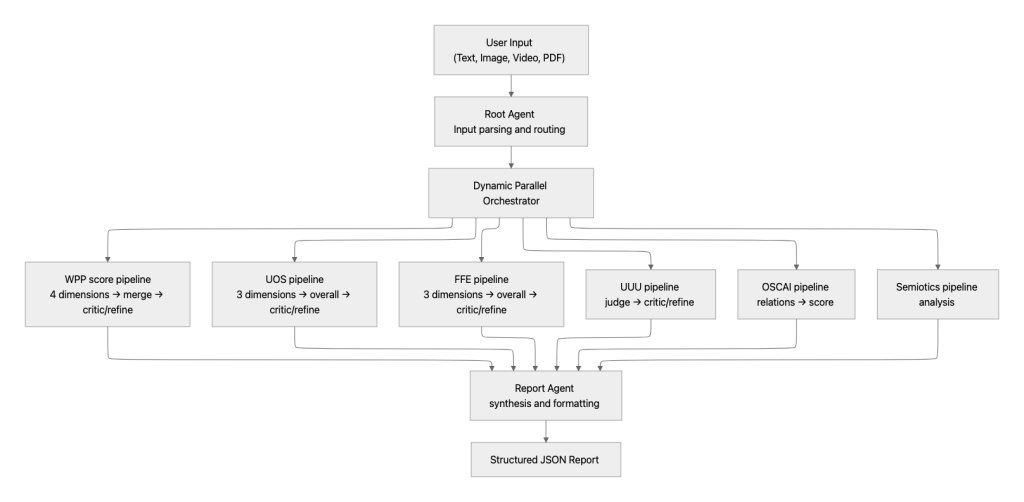
Design and deploy an AI agent, capable of evaluating any marketing campaign idea automatically and consistently, across six industry-grounded creativity frameworks simultaneously. A user submits a campaign idea (text or PDF) via the web UI or API. Then, our multi-agent system evaluates it across all six frameworks in parallel and returns a structured report with dimension-level scores and qualitative commentary in 15–25 seconds.

Goal 2: Benchmark who creates the best ideas: LLMs, humans, and AI agents
The evaluation engine is also the foundation of a creative benchmarking tournament. The second goal is to use the agent as an objective judge to measure and rank the creative output of different players. For this exercise the players have been state-of-the-art LLMs.
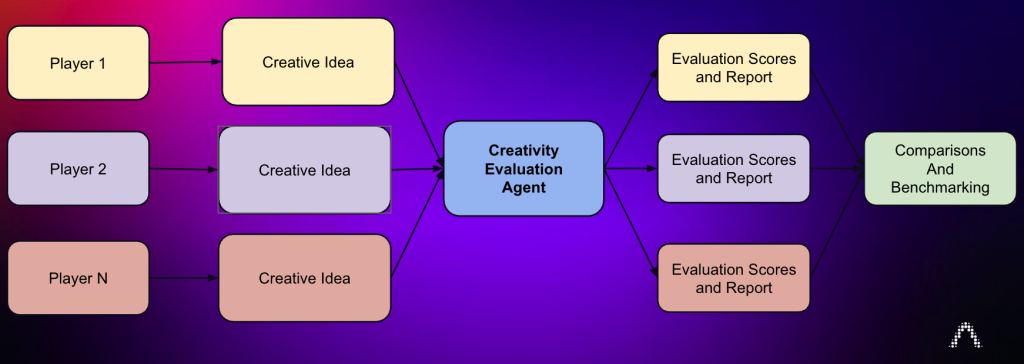
To do this rigorously, we adopted the Glicko2 rating system (also used in games such as chess Elo, Counter Strike and Dota 2), running a round-robin tournament where each player’s ideas compete head-to-head. The result is a continuously updatable creative leaderboard which ranks AI creativity in advertising.
From foundations to architecture
To move from subjective opinion to objective evidence, the system stands on the shoulders of giants, synthesising established psychometrics like the Torrance Tests of Creative Thinking (TTCT) with industry-proven frameworks. The challenge lies in translation: turning these theoretical foundations into an autonomous agent capable of automated creativity evaluation with human-like nuance and explainable logic supported by a confederacy of specialised models.
The multi-agent ecosystem
Rather than relying on a single monolithic judge, the system orchestrates a specialised “squad” of sub-agents, each one encoding a distinct evaluation technique from creativity science or brand strategy. Some measure the quality of the output — how effective, original, and strategically durable the idea is. Others measure the quality of the thinking — how expansive, surprising, and culturally grounded the generative process behind it is. Together, they cover the full spectrum from practical effectiveness to creative cognition.
| Agent | What It Measures | Grounded In |
|---|---|---|
| Effectiveness (WPP) | Does the idea work as a campaign? How sharply framed, how boldly inspired, how relevant, how impactful? | Proprietary WPP creativity framework built around four dimensions of creative excellence, calibrated against real campaign performance across multiple brands and markets. Inspired by research on inspiration published in Harvard Business Review, the framework evaluates the “DNA of what makes ideas inspiring.” |
| Generative Flow (FFE) | How broad and varied is the thinking? Does the idea explore multiple formats, categories, and angles? | FFE (Fluency, Flexibility, Elaboration) dimensions from creativity research, benchmarked against marketing creativity datasets. |
| Divergent Creativity (UOS) | Is the idea useful, original, and surprising? | UOS (Usefulness, Originality, Surprise) framework from divergent thinking literature. |
| Creative Strategist (UUU) | Is the idea unique, unexpected, and unforgettable enough to endure? | UUU (Unique, Unexpected, Unforgettable) brand longevity assessment, utilising multi-domain evaluation techniques. |
| Conceptual Distance (OSCAI) ([OSCAI – LLM Scoring | Open Creativity Scoring](https://openscoring.du.edu/ocsai)) | How far apart are the connected concepts? Distinguishes mundane links from highly original leaps. |
| Semiotics | How is meaning constructed through cultural symbols? Is the creative execution aligned with the intended brand message? | Saussurean sign systems and cultural logic. |
Table 1: Scores description
How the agents work: scoring architecture and self-correction
Every sub-agent is governed by the same rigorous four-part prompt architecture. Each is anchored by a specialised Role that encodes its evaluation lens, followed by a granular Definition of Score that translates abstract dimensions into measurable benchmarks. The core logic is driven by precise Instructions calibrated against few-shot examples drawn from a ground truth library of ideas and historical scores. This architecture feeds into a Critic-Refiner cycle, where specialised Refiner agents challenge initial assessments and resolve contradictions. The refinement doesn’t trigger on every run, but its presence is deliberate: we observed during evaluation that LLMs had a tendency towards optimism in scoring, and this self-correction layer ensures the final output remains robust and consistent.
In other words, the agent descriptions above define what each agent evaluates; the shared architecture is how they all do it.
Aligning sub-agents with human intuition
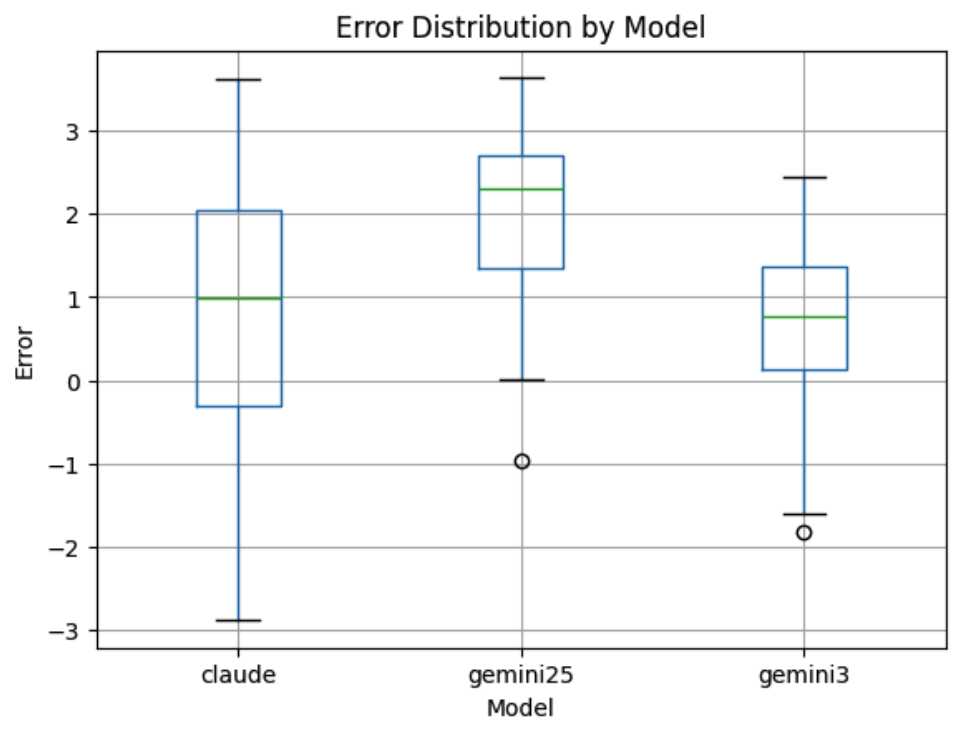
Before trusting the system, we needed to prove it thinks like a human Creative Director. We assembled a Ground Truth dataset in collaboration with WPP creative professionals: 20 campaign ideas, each captured as a title and description, scored by consensus using the WPP effectiveness score. We then ran each idea through our evaluation pipeline across three frontier models and measured the prediction error.
| Model | Avg. Error (Agent vs. Human Scores) |
|---|---|
| Gemini 2.5 | 2.2 |
| Claude Sonnet 4.5 | 1.0 |
| Gemini 3 | 0.7 |
Table 2: Model comparison
Gemini 3 emerged as the definitive choice and was deployed across all sub-agents. We also validated repeatability: the same idea, scored across independent runs, held stable with low standard deviation across all frameworks. The WPP score was the most precise signal, but UOS, FFE, and UUU all showed the same core reliability.
The takeaway: our benchmarks are grounded in data, not AI randomness. Repeatability is a measured property of this system and not an assumption.
Case study
With the agent LLM validated, we moved to a real-world stress test for a furniture company. This challenge asked different LLMs to tackle a nuanced brief rooted in a specific cultural tension: North Asian families with millennial parents and preteen children are living under the same roof but feeling worlds apart — clutter, gaming, and conflicting needs for “me time” vs. “we time” are eroding family connection. The brief demanded ideas that were cross-market, minimal-dialogue, and crucially, not too warm or safe.
Each LLM’s output was run through the full evaluation ecosystem. Every sub-agent independently scored the idea along its respective dimension, and the resulting sub-scores were summed into a single composite total.
To generate the ideas, we used both standalone frontier LLMs (GPT-5, Gemini 3, Claude 4.5 Sonnet) and WPP’s Creative Brain — a multi-agent ideation system available through WPP Open’s Agent Hub that wraps an LLM in a structured creative process, guiding it through strategic reframing, lateral thinking, and iterative refinement before producing a final concept. By testing Creative Brain alongside standalone models, the challenge reveals how much of creative quality comes from the model itself versus the orchestration around it.
Because the raw evaluation pillars operated on different scales — WPP uses a 0–12 sum, FFE averages to 0–3, while UOS and UUU average to 0–5 — direct comparison across pillars was misleading. All scores were normalized to a common 0–10 range so that each pillar contributes equally to a maximum total of 40.
It should be noted that two scoring sub-agents, OSCAI and Semiotics were excluded from the evaluations because of their high scoring variance (see Section 3.6 of the technical report).
1. GPT-5: the gamification grandmaster
GPT-5 led the pack with a total score of 37.44. Its winning strategy, “Co‑op Mode: Make Home Happen,” reframed the entire experience of home life as a collaborative video game the whole family plays together. The central insight: small home changes don’t stick because they don’t feel rewarding but games do. By turning clutter into the “boss” and the furniture company’s solutions into unlockable “side quests,” GPT-5 built an end-to-end ecosystem that made organisation feel joyful rather than obligatory.
| Pillar | Initiative | Description & Impact |
|---|---|---|
| 1. Launch Film | “Clutter is the Boss” | A 60s hero film where a family’s living room transforms into a co‑op game interface—prompts like “Inventory Full” and “Find Calm” appear as they “equip” products to defeat the clutter boss. No spoken lines, region-agnostic SFX. Reframes organisation as play; makes the campaign cross-market viable without localisation. |
| 2. Social/UGC | “Home Side Quests” | Weekly micro-challenges (under 10 min) like “Create a charging dock” or “Flip sofa to study.” Augmented Reality (AR) filters add level meters and badges; families post before/afters to the #CoOpHome Challenge with creator duets from gaming and parent influencers. Drives sustained engagement and organic reach through participatory content. |
| 3. Retail/Shoppable | “Co‑op Kits” | Curated in-store and online bundles organised by mission—Study Calm, Party Fast Reset, Balcony Green Break—each bundling storage + lighting + organisers. Every kit includes a QR “Quest Card” guiding micro-steps with estimated time saved. Turns the purchase into the start of a new quest; bridges content to commerce. |
| 4. In-Store Experience | “Demo Levels” | Stores host timed tidy-up challenges where kids and parents compete together to reorganise a mock room against the clock. Winners earn collectible stickers and discount codes. Transforms the retail visit into an extension of the campaign’s game logic; drives foot traffic through experiential play. |
| 5. Digital Ads | “Skip the Clutter” | YouTube bumpers using skip-button logic—”Skip the clutter in 3…2…1″—to land a single, punchy product solve within seconds. Leverages ad format mechanics as creative device; delivers product utility in pre-roll. |
Table 3: Campaign idea produced by GPT-5.
The campaign’s minimal-dialogue, SFX-driven creative approach ensured cross-market viability across North Asian markets without localisation, while the consistent game language (“side quests,” “boss,” “level up,” “equip”) created a unified system that scored perfect on coherence. Every asset closed with the same recontextualised tagline: “Furniture company. Make Home Happen.”, framed not as an aspiration, but as a mission objective.
2. Creative Brain powered by Gemini: the multiverse architect
The Creative Brain powered by Gemini followed closely with a score of 36.95. Its “Room-Sync Chronicles” campaign took a fundamentally different approach: rather than gamifying the solution, it gamified the problem. The central reframe, that every piece of “clutter” in a preteen’s bedroom is actually a physical anchor for their digital and imagined worlds — gave parents a radically empathetic lens through which to see their child’s space. The furniture company storage wasn’t positioned as a way to “hide the mess” but as a way to “power the multiverse.”
| Pillar | Initiative | Description & Impact |
|---|---|---|
| 1. Launch Film | “Reality Reboot” | A cinematic 60s spot where a mother opens her son’s door and sees a mess—but the room “glitches” into a high-fidelity game landscape. A box unit becomes a loot chest; a gaming chair becomes a pilot’s cockpit. VFX borrows from game trailers. Subverts the “messy room” trope by revealing the child’s imaginative reality; makes furniture feel epic. |
| 2. Narrative Arc | “Co-Op Reorganisation” | The film follows mother and son “co-oping” a reorganisation — but the goal isn’t to clean. It’s to “optimise the map” for his next quest. Storage becomes power-ups that expand the room’s modes: gaming arena, creative studio, family bonding zone. Reframes tidying as collaborative strategic upgrade, not parental demand. |
| 3. Social/AR | “Skin Your Room” | A social platform where kids apply AR filters to their real rooms, overlaying fantasy skins that reveal the “epic reality” hidden behind the furniture. Kids share their “skinned” rooms with parents to bridge the perception gap. |
| 4. Brand Positioning | “Powering the Multiverse” | Storage is repositioned as an identity enabler for developing preteens — a tool that supports creativity, gaming, and emerging selfhood. Storage doesn’t organise a room; it powers the multiverse being built inside it. Elevates product value proposition from functional to emotional and developmental. |
| 5. Strategic Inversion | Child-First Perspective | The campaign validates the preteen’s perspective first, then invites the parent in, inverting the typical home-brand default of centering the adult buyer’s desire for order. Boldest strategic choice in the cohort; highest risk, highest differentiation. |
Table 4: Campaign idea produced by Creative Brain.
Underlying the entire campaign was a provocative strategic choice that the evaluator flagged as both its greatest strength and its primary risk: centering the child’s worldview over the parent’s. Where most home brands default to the adult buyer’s desire for order, Room-Sync starts from the preteen’s experience and invites the parent to see through their eyes. This inversion earned it the cohort’s highest Unforgettable score, but the Creative Evaluation Agent noted the heavy RPG metaphor might alienate parents unfamiliar with gaming culture.
3. Claude Sonnet 4.5: the reality show provocateur
Claude Sonnet 4.5 followed with a score of 35.12. Its “The Remodel Squad” strategy took the most grounded, human-first approach of the cohort. Where GPT-5 and Gemini leaned into fantasy and gamification, Claude leaned into documentary authenticity, positioning real family friction not as a problem to be solved but as the raw material for genuine connection. The core creative bet: audiences are tired of aspirational perfection and will respond to the messy, funny, emotional truth of families actually trying to share space.
| Pillar | Initiative | Description & Impact |
|---|---|---|
| 1. Launch Film | “The Beautiful Mess” | A 60s hero spot showing a parent-child duo hilariously debating the furniture company’s storage solutions, arguing over shelf heights, drawer labels, and who gets the corner nook. The punchline: they both want the same thing. Designed to feel like a documentary moment, not an ad; builds instant relatability. |
| 2. Content Series | “The Remodel Squad” | 6–8 episodes (5–8 min each) where real families nominate the room causing the most conflict. One preteen + one parent form a “Remodel Squad” to transform it using the company’s solutions but they must agree on every single decision. Captures hilarious negotiations, compromises, and breakthroughs. Friction becomes the creative fuel; the format is inherently dramatic and bingeable. |
| 3. Episode Structure | Three-Act Arc | Each episode follows: (1) the conflict audit (what’s wrong, who’s to blame), (2) the design negotiation (friction-fueled creative process), (3) the heartwarming reveal — not a “ta-da” moment, but the family’s first natural interaction in the new space. Emotional payoff is relational, not just spatial. |
| 4. Social/Viral | “15-Second Cutdowns” | Bite-sized content isolating the series’ most relatable moments: funniest negotiation standoffs, most dramatic before/afters, quiet breakthrough moments. Designed as standalone viral units that drive viewership back to full episodes. Engineered for shareability across short-form platforms. |
| 5. Interactive Tool | “Conflict Zone” AR App | Families scan their own problem rooms and collaboratively visualise the company’s solutions in situ. Families can tag their room’s “conflict level” and share proposed redesigns. Emphasis on joint decision-making over individual play. Extends the show’s premise into every family’s home; sparks “productive arguments.” |
Table 5: Campaign idea produced by Claude Sonnet 4.5.
The campaign’s greatest strength was its emotional granularity. Rather than offering a single visual payoff, each episode promised a different family, a different room, and a different set of negotiations — creating a content engine with built-in variety and repeatability. The Creativity Evaluation Agent awarded it the cohort’s highest Usefulness score, for its practical alignment with the brief’s tone requirements, but noted that reality-renovation formats carry inherent category familiarity, reflected in its lower Uniqueness score. Every piece of content closed with the family in their transformed space and the line: “Make Home Happen.”
4. Gemini 3: the diplomatic provocateur
Gemini 3 rounded out the cohort with a score of 32.48. Its “The Domestic Peace Accords” took the boldest tonal swing of the group, making a singular creative bet: position the furniture company’s products as essential diplomatic tools to resolve the “cold war” between generations, executed entirely through the visual grammar of geopolitical thrillers. Where other entries built broad ecosystems, this idea invested everything in the power of one perfectly realised metaphor.
| Pillar | Initiative | Description & Impact |
|---|---|---|
| 1. Core Metaphor | “Furniture as Diplomacy” | The parent-preteen conflict is reframed as a genuine geopolitical standoff — a “cold war” between factions with irreconcilable demands (minimalist calm vs. messy independence) over limited territory (square footage). The products are repositioned as “diplomatic tools” that broker peace. Elevates a mundane domestic problem to dramatic, absurd, memorable heights. |
| 2. Launch Film Series | “The Negotiations” | Spots filmed in the style of high-stakes political thrillers, Tinker Tailor Soldier Spy meets a bookcase. Parent and preteen sit at opposite ends of a long table in a dim, dramatically lit room, sliding “terms” across: a pegboard for gaming gear in exchange for a clean floor; a sound-absorbing curtain for privacy in exchange for family dinner attendance. Every product is a bargaining chip with a story. |
| 3. Visual Payoff | “Treaty Signed” | Each spot resolves in a single, sharp cut: the dim negotiation room gives way to a bright, airy, reorganised living space where both parties co-exist happily. The tonal whiplash from spy-thriller gravity to domestic warmth is the joke. Designed to be the defining shareable moment audiences remember and recount. |
| 4. Product as Plot | Narrative Integration | Unlike campaigns where products are set dressing, every item functions as a narrative object, a concession, a peace offering, a treaty clause. The pegboard isn’t “organised storage”; it’s the term that bought a clean floor. The bin is the clause that secured family movie night. Gives each product a story and a reason for being that transcends traditional placement. |
| 5. Tagline Reframe | “Make Home Happen” as Treaty | The company’s existing tagline is repositioned not as an aspiration but as the terms of a negotiated truce, smart organisation that lets parents reclaim visual calm while granting preteens the “cool functional territory” they demand. Breathes new strategic life into existing brand language. |
Table 6: Campaign idea produced by Gemini 3.
The Domestic Peace Accords had the strongest semiotic coherence – every element, from language (“cold war,” “treaty,” “terms”) to visual style (dim thriller lighting vs. bright domestic reveal) to product role (bargaining chips), reinforced one unified meaning system without contradiction while it also scored the highest Unexpected rating. However, its singular focus proved to be a double-edged sword: by investing entirely in one metaphor executed through one format (film spots), it presented no secondary executions, platforms, or conceptual categories**,** pulling its Total FFE down.
The top contenders
| Model | WPP Score | FFE score | UOS score | UUU score | Total Score |
|---|---|---|---|---|---|
| GPT-5 | 9.50 | 10.00 | 9.60 | 8.34 | 37.44 |
| Gemini 3 (Creative Brain) | 9.21 | 10.00 | 9.40 | 8.34 | 36.95 |
| Claude Sonnet 4.5 | 8.92 | 10.00 | 8.60 | 7.60 | 35.12 |
| Gemini 3 | 8.75 | 6.67 | 9.20 | 7.86 | 32.48 |
Table 7: Final individual and total scores of the 4 different LLMs for the furniture company case study.
Three of four models scored a perfect FFE (10.00), meaning raw creative thinking was comparable across the board. The separation came from WPP Score and UOS.
GPT-5 posted the highest WPP (9.50). The WPP Agent cited “multiple direct pathways to purchase and engagement” and noted “exceptional focus on the stated business challenge.” The UOS Agent awarded 9.60: “meticulously crafted, creatively addressing every aspect of the client’s brief with seamless logical flow.”
Creative Brain matched GPT-5 on FFE (10.00) and UUU (8.34). The UUU Agent noted “the core visual of the room ‘glitching’ into an RPG world creates an incredibly strong and distinct defining moment.” The WPP gap (9.21 vs. 9.50) traced to a coherence flag: “the heavy reliance on gaming metaphors might alienate or confuse parents who are not immersed in digital culture.”
Claude Sonnet 4.5 earned the cohort’s highest Usefulness score — the UOS Agent praised its “practical alignment with the client’s brief, particularly in embracing realistic family conflict rather than a ‘too warm or safe’ tone.” The UUU Agent observed it “takes a common format (reality renovation show) and infuses it with a fresh twist” — but the format itself limited differentiation.
Gemini 3 earned the highest Unexpected rating — the UUU Agent called the “juxtaposition of the mundane struggle for space with the gravitas of political thriller negotiations a brilliant flip.” But the FFE Agent recorded zero Flexibility: “a single, unified marketing campaign concept” with “no multiple distinct conceptual categories,” and the WPP Agent noted it “doesn’t create a new utility or platform.”
The creative Elo tournament
A single brief can’t tell us which model is consistently creative. To answer that, we expanded the experiment: each model was given multiple diverse briefs spanning different brands, categories, and creative challenges, and every output was scored by the same evaluation pipeline.
We needed a ranking system that captured consistency against competition — not just average scores. An Elo rating is a numerical score that reflects a competitor’s relative skill based purely on head-to-head outcomes. The higher the rating, the stronger the performer. We turned to Glicko-2, the rating algorithm used in competitive chess, CS:GO, and Dota 2. Every head-to-head match is a data point: if idea A beats idea B, A gains rating and B loses it. Glicko-2 also tracks rating deviation (RD) — a confidence interval that shrinks with more matches.
The players
- GPT-5
- Gemini 3
- Gemini 2.5
- Claude Sonnet 4.5
- Creative Brain — built on Gemini 3 with an optimised prompting architecture
Four models received a standardised prompt. The Creative Brain received the same brief but processed it through its own multi-agent ideation pipeline — testing whether orchestration outperforms raw model capability.
The Creativity Evaluation Agent judged every idea independently. An orchestration engine simulated head-to-head matches by comparing normalised scores for the same brief. The winner of the matches is the one that has higher normalised composite score on common metrics. The result: 210 unique creative matches across 5 models and 14 global brands, run over 3 iterations.
The results
Ranked across WPP Score
| Rank | Player | Rating | RD |
|---|---|---|---|
| 🥇 | Creative Brain (Gemini 3) | 1889 | 84.8 |
| 🥈 | GPT-5 | 1858 | 92.3 |
| 🥉 | Claude Sonnet 4.5 | 1529 | 83.9 |
| 4 | Gemini 3 | 1169 | 90.7 |
| 5 | Gemini 2.5 | 962 | 104.2 |
Table 8: Elo ratings on the WPP score.
Ranked across all frameworks
| Rank | Player | Rating | RD |
|---|---|---|---|
| 🥇 | GPT-5 | 1940 | 84.3 |
| 🥈 | Creative Brain (Gemini 3) | 1927 | 79.2 |
| 🥉 | Claude Sonnet 4.5 | 1378 | 77.4 |
| 4 | Gemini 3 | 1216 | 86.6 |
| 5 | Gemini 2.5 | 861 | 106.3 |
Table 9: Elo ratings across all frameworks.
Creative Brain leads on WPP criteria — delivering a measurable advantage when judged against industry-specific creative standards. The gap between Creative Brain and standalone Gemini 3 is nearly 720 rating points. GPT-5 is the strongest all-rounder — topping the all-frameworks leaderboard with ideas that score well across the broadest range of creative dimensions.
Key insights & findings
- Creative Brain dramatically outperforms standalone Gemini 3. Same underlying model, ~720 rating point gap. The structured ideation process consistently elevated creative output beyond what Gemini 3 could produce alone. Notably, Creative Brain was not optimised against the WPP scoring criteria — its strong performance emerged naturally from a better creative process.
- The right judge model is foundational. It can be seen in Figure 4 that Gemini 2.5 averaged 2.2 error against human ground truth; Claude Sonnet narrowed it to 1.0; Gemini 3 achieved 0.7. Selecting the judge model determines whether the entire system tracks human judgment or drifts from it.
- Human judgment remains essential at the margins. When total scores differ by less than a point — as with GPT-5 (23.37) vs. Creative Brain (22.92) — the agent surfaces meaningfully different trade-offs that scores alone cannot resolve. The system’s value is in ensuring the right ideas and evidence reach the table, not replacing human judgment.
- Evaluator reliability is a measured property, not an assumption. Across repeated independent runs on the same ideas, scores held stable with low standard deviation. This repeatability is what allows every other finding to be treated as signal rather than noise.
Conclusion & impact
This work demonstrates that scalable, repeatable creative evaluation using LLMs is practical today, provided the system is built with the right scaffolding: calibrated judge models, few-shot anchoring, multi-dimensional scoring, and cross-model validation.
In practice, the Creativity Evaluation Agent enables:
- Faster iteration — stress-test dozens of creative directions in minutes rather than weeks, before committing production budgets.
- Comparable benchmarking — evaluate models, prompting strategies, and agentic architectures on common ground with a shared, reproducible rubric.
- Diagnosable feedback — learn not just that an idea underperformed, but where and why, with dimension-level scores and qualitative commentary that teams can act on immediately.
- Creative governance — an auditable, explainable evaluation process that scales alongside the growing volume of AI-generated creative, giving organisations confidence and consistency as they adopt generative tools.
Ready to explore the specifics? Read our full technical deep dive into the Creativity Evaluation Agent Pod for a closer look at our methodology.
Disclaimer: This content was created with AI assistance. All research and conclusions are the work of WPP Research.

