Creative ideas are the primary driver of advertising impact, yet evaluating them at scale remains stubbornly subjective — human panels are expensive, slow, inconsistent across evaluators, and impossible to run repeatedly as the volume of AI-generated concepts grows. The core problem is that creativity is multidimensional: a single aggregate score fails to capture whether an idea is original, strategically aligned, culturally resonant, or memorable, and without a shared, repeatable rubric, teams cannot meaningfully compare outputs across models, prompts, or campaigns. To address this, we built the Creativity Evaluation Agent, which scores marketing ideas in parallel across six established creativity frameworks — an Internal WPP, UOS, FFE, UUU, OSCAI, and Semiotics scores — using specialised Large Language Model (LLM) sub-agents with critic-refiner loops to ensure consistency, returning dimension-level scores alongside qualitative commentary in a single structured report. Calibrated against human expert ground truth, the system achieved a scoring error as low as 0.7 points (Gemini 3) with high repeatability on the internal WPP score framework (σ ≈ 0.21), and in a 210-match tournament across 14 global brands, it reliably differentiated creative quality between five frontier models — revealing that a specialised agentic creative system consistently outperformed vanilla LLMs given the same brief, giving marketing teams a fast, interpretable, and auditable way to benchmark and iterate on creative output before committing production resources.
This document details the technical architecture, calibration methodology, and experimental design underlying the system built to address these gaps. For results and strategic findings, read our blog post instead.
Problem statement and motivation
Everyone agrees creativity matters in marketing. Nobody agrees on how to measure it. Put the same campaign idea in front of five reviewers and you’ll get five different scores. One loves the visual metaphor, another thinks the tagline falls flat, a third is just tired after reviewing thirty concepts before lunch. The scores reflect taste and circumstance as much as they reflect the work. This is fine when you’re picking between two finalist campaigns in a boardroom — it falls apart the moment you need to evaluate at scale. And scale is exactly what modern marketing demands. Teams are generating more ideas than ever, increasingly with the help of generative AI. They need to screen hundreds of concepts quickly, understand what specifically makes one idea stronger than another, and benchmark creative output across different models, prompts, teams, and time periods. A human review panel can do the first job slowly, the second job inconsistently, and the third job barely at all—while being expensive to convene every time. The core issues are straightforward:
- Subjectivity — without a shared rubric, two reviewers scoring the same idea can land in completely different places.
- Scalability — manual evaluation doesn’t survive contact with hundreds of ideas per sprint.
- Feedback quality — a score without explanation is useless for iteration; explanations vary wildly across evaluators.
- Cost and repeatability — assembling expert panels is slow and expensive, and running the same panel twice doesn’t guarantee the same results.
What’s missing is a system that can apply structured, reproducible, explainable creativity assessment across large volumes of work — fast enough to be useful and consistent enough to be trusted.
1. Introduction and solution overview
Evaluating marketing creativity at scale demands more than a single score from a single judge. The Creativity Evaluation Agent, built on Google’s Agent Development Kit (ADK), extends the established LLM-as-a-Judge paradigm by introducing a multi-agent system in which specialised sub-agents score marketing ideas across six complementary creativity frameworks, each covering a distinct slice of what practitioners consider “good creativity.” Every scoring sub-agent is grounded through few-shot examples that teach the underlying LLM how the creative dimension it owns should be measured, narrowing the gap between automated and human judgement. The system accepts text, image, video, and PDF inputs, runs framework evaluations in parallel, and returns dimension-level scores together with qualitative commentary. It is accessible through both an API and a web UI.
2. Technical approach
2.1. Architecture overview
At a high level, a user’s idea is received by a Root Agent, which parses the input and routes it to a Dynamic Parallel Orchestrator. The orchestrator spins up only the scoring pipelines the user has requested, runs them concurrently, and hands their outputs to a Report Agent that merges everything into a single structured JSON response.
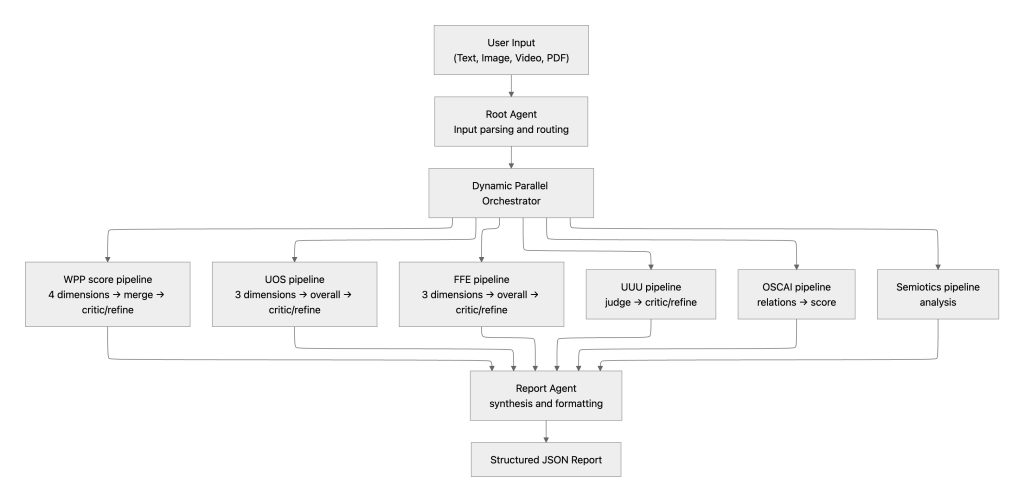
2.2. Custom orchestration engine
The core implementation is the Creativity Evaluation Agent, a custom ADK BaseAgent. Its behaviour breaks down as follows:
- Root Agent. The user-facing entry point. It can answer questions, hold a conversation, and — when the user supplies a creative idea — forward it for evaluation. It decides which frameworks to invoke based on the user’s request.
- Dynamic pipeline construction. Pipelines are not built ahead of time. Based on what the user asks for, the orchestrator assembles only the relevant evaluation chains, then executes them in parallel.
- Critic–refiner loop. After initial scoring, each pipeline runs a bounded critic–refiner cycle (up to two iterations) in which a critic agent reviews the scores for obvious errors or inconsistencies. If the critic flags an issue, the refiner adjusts before the result is finalised.
- Report Agent. Once all pipelines complete, this agent compiles dimension-level scores and qualitative commentary into a single, consistently formatted output. When the user has submitted multiple ideas, the report includes a comparative analysis.
Each scoring pipeline is built around an LlmAgent instance initialised with a detailed system message encoding its evaluation lens, together with few-shot examples that anchor outputs close to human scoring behaviour. Scores are emitted as continuous values (e.g. 1.2, 3.7) rather than discrete integers, matching the granularity of the ground-truth datasets. The six pipelines are:
- WPP Score Pipeline. Scores ideas against a proprietary WPP creativity framework built around four dimensions:
- how sharply the idea frames the business challenge, not just the marketing opportunity
- how boldly it challenges category convention and subverts clichés
- how authentically the proposed solution fits the brand and resonates with the audience) and
- the scale of measurable growth and emotional response it is designed to deliver
- Each dimension is scored 1–3 points, composited into an index ranging 0–12. The framework was calibrated against real-world campaign performance across multiple brands and markets. Few-shot examples are drawn from WPP’s internal archive of historically scored campaigns.
- Usefulness, Originality and Suprise (UOS) Pipeline. Evaluates the classic definition of divergent creative value through three dimensions: Usefulness (does it solve a real problem and align with the brief’s constraints?), Originality (does it approach the problem in a novel way?), and Surprise (does it deliver an unexpected twist that captures attention?). The three dimension scores are aggregated into an overall UOS score.
- Fluency, Flexibility and Elaboration (FFE) Pipeline. Quantifies the “mental engine” behind the idea through three dimensions: Fluency (how many distinct, relevant ideas are presented), Flexibility (how many different conceptual categories are explored), and Elaboration (how richly detailed and refined the idea is). Grounded in creativity research literature and benchmarked against marketing creativity datasets. Few-shot examples are generated using Torrance-style divergent thinking tasks (see Section 4.1).
- Unique, Unexpected and Unforgettable (UUU) Pipeline. Assesses brand longevity through the lens of a Creative Strategist: Unique (could only this idea deliver this message in this way?), Unexpected (does it subvert expectations and force re-evaluation?), and Unforgettable (does it create a defining moment that lives rent-free in the audience’s mind?). Each dimension is scored as a continuous value and averaged into an overall UUU score.
- OSCAI Pipeline. A two-stage pipeline for measuring conceptual distance. First, a sub-agent extracts semantic relations from the idea (e.g., man → eats → apple). Those relations are sent to the OSCAI API, maintained by the framework’s original authors, which scores each relation’s originality — distinguishing mundane links (a chef cooks dinner) from highly original relationships (a clown teaches mathematics). The returned scores quantify the creative leap at the heart of the idea.
- Semiotics Pipeline. Applies the Saussurean principles of sign systems to decode how meaning is constructed through cultural symbols. The sub-agent analyses Denotation (literal content), Connotation (implied meaning), Myth (cultural narratives reinforced or challenged), the Semiotic Relation (additive, contradictory, etc.), Risks or tensions, and produces a Semiotic Coherence Score (0–3). Unlike the other pipelines, no few-shot examples are used — evaluation relies on the model’s inherent understanding of semiotic theory.
2.3. Score normalization
The six frameworks operate on different native scales:
| Framework | Native scoring | Range |
|---|---|---|
| WPP Score | Sum of 4 dimensions, each 0–3 | 0–12 |
| FFE | Average of 3 dimensions, each 0–3 | 0–3 |
| UOS | Average of 3 dimensions, each 0–5 | 0–5 |
| UUU | Average of 3 dimensions, each 0–5 | 0–5 |
| OSCAI | Single score | 0–5 |
| Semiotics | Coherence score | 0–3 |
Table 1: Creativity scores and their range. Direct comparison or summation across frameworks is misleading without normalisation. The following procedure is applied:
- Convert sums to averages. The WPP Score (a sum of four 0–3 dimensions) is divided by 4 to produce a 0–3 average, making it structurally comparable to other averaged scores.
- Rescale to a common 0–10 range. Each framework’s score is divided by its native maximum and multiplied by 10:
normalised_score = (raw_score / max_score) × 10
- Composite total. The 4 normalised pillar scores (WPP, FFE, UOS, UUU) are summed into a composite total with a maximum of 40, each pillar contributing equally.
OSCAI and Semiotics are reported as standalone scores and are not included in the composite total. This decision was made because OSCAI depends on an external API with different reliability characteristics, and both OSCAI and Semiotics showed higher inter-run variability (σ ≈ 0.80, see Section 4.3), which would add noise to the composite.
2.4. Infrastructure and deployment
| Concern | Technology |
|---|---|
| Multi-agent orchestration | ADK |
| Compute | Google Cloud Run |
| LLM inference | Vertex AI — Gemini 3 Pro as the primary judge model |
| Observability | Cloud Logging + Cloud Trace |
| Container registry | Artifact Registry |
| Agent-to-agent protocol | A2A |
Table 2: Employed Google teck stack.
3. Ground truth data and system evaluation
3.1 Dataset overview
Reliable automated scoring requires credible ground truth. Because no single public dataset covers all six frameworks, a combination of historical data and synthetically generated ground truth was used.
3.2. WPP score — historical human judgements
The ground-truth dataset comes from WPP’s internal archive of marketing campaign ideas submitted between 2020 and 2023. Creative professionals scored each idea across the WPP dimensions. From this corpus, 6 scored ideas were selected as few-shot examples for the scoring sub-agent and 10 additional ideas were reserved for its critic agent.
3.3. FFE — synthetic data via Torrance-style tasks
Few-shot examples for the FFE framework were generated using Gemini prompted with tasks modelled on the Torrance Tests of Creative Thinking. Each example pairs a divergent-thinking task, a response, a score, and a justification. For instance:
Example 1 (Score 0):
- Task: Please list unusual uses of a plastic bottle.
- Response: 1. Plant a seed in it. 2. Use it to water plants by poking holes. 3. Cut it in half to make a small planter. 4. Use it to store extra fertiliser.
- Justification: All ideas fall under a single, narrow category (Gardening / Horticulture). No conceptual shift is demonstrated.
3.4. UOS & UUU — community-sourced creative writing
No pre-existing ground truth was available for these two frameworks, so it was constructed in three steps:
- Source corpus. The Creative Storytelling dataset (stories from r/WritingPrompts on Hugging Face) was used as raw material.
- Quality stratification. Stories were sorted by upvotes; 11 highly upvoted and 11 low-voted examples were selected to represent the ends of the quality spectrum.
- Automated annotation. These 22 stories, together with the formal definitions of the UOS and UUU dimensions, were fed to Gemini, which produced scored examples that serve as the few-shot ground truth for both frameworks.
3.5. Scoring format
All scoring sub-agents output continuous values (e.g. 1.2, 2.8) rather than rounding to integers. This decision was made to stay consistent with the WPP ground-truth scores, which are themselves continuous, and to preserve finer-grained distinctions between ideas.
3.6. Variability analysis
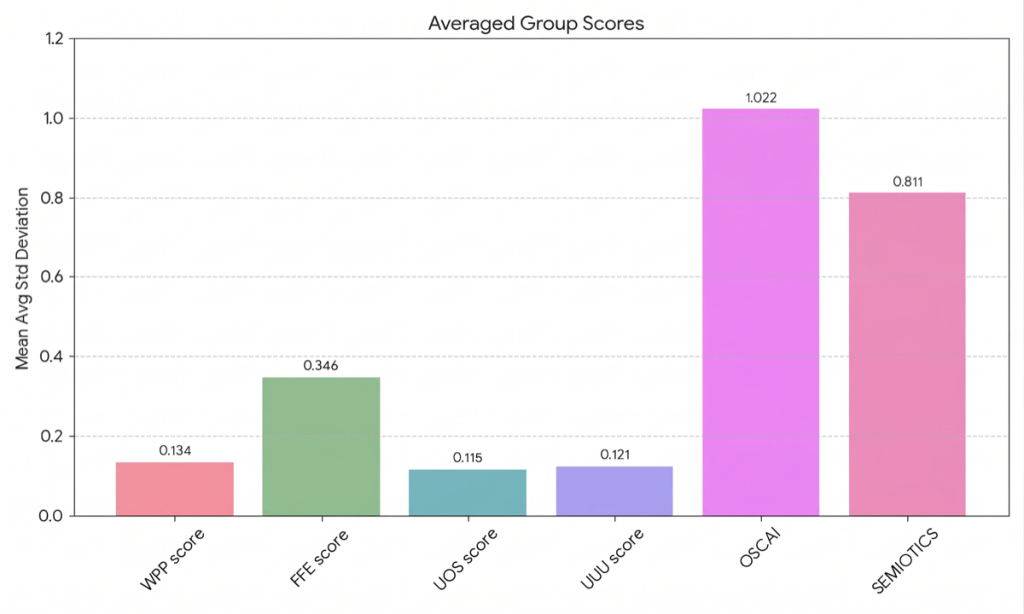
Reliability was assessed by scoring 55 campaign ideas (one per model) for a popular beverage brand, three times each. Each of the 5 ideas (one per AI model) was rated 3 times by the benchmark agent, and the standard deviation (std) across those 3 runs was computed per score. Each bar shows the average std across all 5 models, so taller bars mean the agent scores that dimension less consistently.
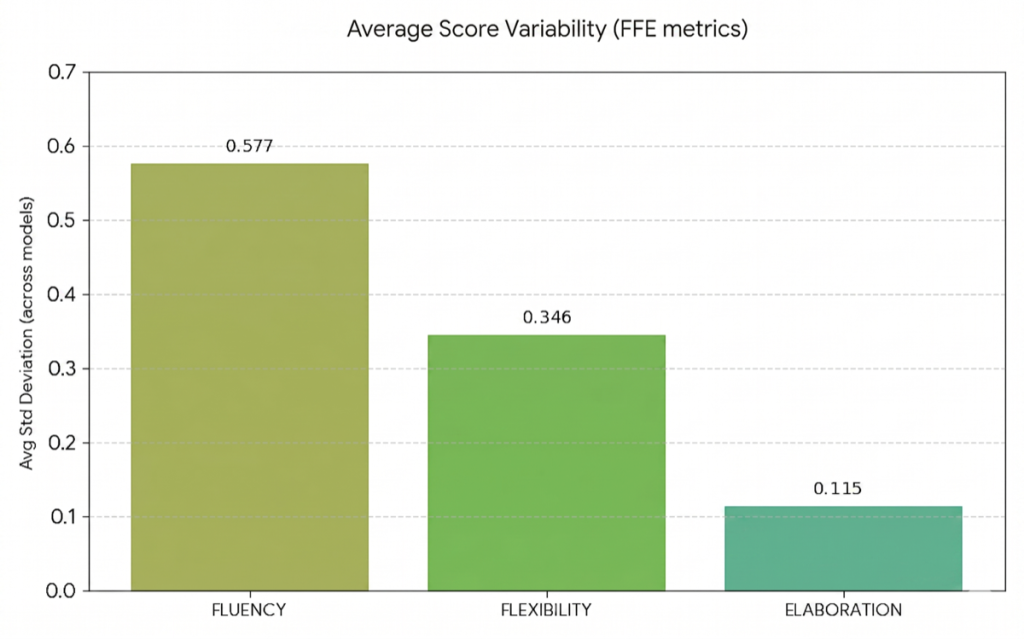
- FFE (Fluency, Flexibility and Elaboration) score shows moderate variability with average std ~ 0.3. Further examination of each constituent creativity aspect evaluated by the FFE score, showed that the deviation is skewed because of Fluency’s variance. This can be due to how Fluency is defined, which is “Evaluate how many distinct, relevant ideas or solutions are presented. Count only meaningful and contextually appropriate ones (avoid repetition or vague statements).” — an inherently count-based metric where the boundary between “distinct” and “overlapping” ideas introduces subjective judgment for an LLM.
- OSCAI & Semiotics show moderate variability with average std ~0.8, which directly motivated their exclusion from the composite tournament score.
4. LLM evaluation tournament
Full tournament results and key findings are covered in the blog post. This section documents the experimental design, technical implementation, per-framework results, and supplementary analysis.
4.1 Experimental design
Players.
| Player | Description |
|---|---|
| GPT-5 | Standalone, standardised prompt |
| Gemini 3 | Standalone, standardised prompt |
| Gemini 2.5 | Standalone, standardised prompt |
| Claude Sonnet 4.5 | Standalone, standardised prompt |
| Creative Brain | WPP’s multi-agent ideation system, built on Gemini 3 |
Table 3: The LLMs that took part in the evaluation tournament. Prompt design. Four standalone models received a standardised, neutral prompt to ensure a level playing field:
“Give me a creative marketing idea/campaign based on the brief. Your output must have a title and three sections: Challenge, Core Idea, and Execution.”
The Creative Brain received the same brief but processed it through its own multi-agent ideation pipeline — testing whether agentic orchestration outperforms raw model capability given identical inputs. Briefs. Each model generated ideas for 14 global brands spanning different categories and creative challenges. Iterations. Each model–brand combination was run 3 times, producing independent idea generations to account for output variance.
4.2. Implementation details
Scoring. Gemini 3 was selected as the LLM that powered our scoring sub-agents. Rather than relying on side-by-side LLM comparisons (which can be inconsistent), the Creativity Evaluation Agent judged every idea independently, generating a structured creativity report with raw scores across all frameworks. This independent-scoring approach means each idea has a self-contained evaluation record that can be compared post hoc, eliminating ordering effects that plague pairwise LLM judging. Match simulation. An orchestration engine simulated head-to-head matches by computing the normalised score average across all evaluated frameworks for each idea on the same brief. Normalisation was applied per-framework to prevent any single framework from dominating (e.g., WPP scores range 0–12 while UUU averages range 1–5). For each brief, every pair of models was matched: the model with the higher normalised average won the match, the other lost. Draws were not permitted; in the event of an exact tie on normalised average, the match was recorded as a draw in Glicko-2 (outcome = 0.5). Glicko-2 parameters.
| Parameter | Value | Rationale |
|---|---|---|
| Initial rating (μ₀) | 1500 | Standard Glicko-2 default |
| Initial rating deviation (RD₀) | 350 | Standard Glicko-2 default; reflects maximum uncertainty |
| System volatility (σ) | 0.06 | Standard default; controls expected rating fluctuation per period |
| Convergence tolerance (τ) | 0.000001 | For the iterative volatility update step |
Table 4: Glicko-2 parameter initialisation. Ratings were updated after each complete round-robin cycle across all 14 briefs before proceeding to the next iteration. This means each “rating period” contained C(5,2) × 14 = 140 matches (every pair of 5 models on every brief), and three rating periods were processed in sequence for the three iterations. Scale. Total matches: 3 iterations × 10 pairs × 14 briefs × (1 match per pair-brief) = 210 unique creative matches across the tournament per ranking method. For per-framework rankings, the same 210-match structure was applied but using the single-framework score (normalised) rather than the cross-framework composite.
4.3 Per-framework leaderboards
To understand where each model’s strengths and weaknesses lie, the same Glicko-2 tournament was run using each individual evaluation framework’s scores as the match-outcome criterion. The results reveal meaningfully different competitive profiles across creative dimensions. We omit the WPP and the aggregate Elo scores since they are available in the executive summary. Additionally we omit the Semiotics and OSCAI Elo scores due to their high scoring variance.
4.3.1 FFE (Fluency, Flexibility, Elaboration)
| Rank | Player | Rating | RD |
|---|---|---|---|
| 🥇 | GPT-5 | 1895 | 88.4 |
| 🥈 | Creative Brain (Gemini 3) | 1651 | 71.8 |
| 🥉 | Claude Sonnet 4.5 | 1583 | 72.2 |
| 4 | Gemini 3 | 1358 | 77.8 |
| 5 | Gemini 2.5 | 1285 | 74.1 |
Table 5: Elo ratings on FFE score. GPT-5 leads comfortably on FFE metrics. The gap between Creative Brain and Claude Sonnet 4.5 is narrow (~68 points), suggesting comparable idea elaboration depth. All Rating deviation (RD) values are below 89, indicating stable ratings.
4.3.2 UOS (Uniqueness, Originality, Surprise)
| Rank | Player | Rating | RD |
|---|---|---|---|
| 🥇 | Creative Brain (Gemini 3) | 2006 | 95.5 |
| 🥈 | GPT-5 | 1657 | 83.6 |
| 🥉 | Gemini 3 | 1567 | 81.7 |
| 4 | Claude Sonnet 4.5 | 1283 | 84.7 |
| 5 | Gemini 2.5 | 1009 | 129.0 |
Table 6: Elo ratings on UOS score. Creative Brain dominates originality, with a 349-point lead over GPT-5 — the widest gap between the top two players in any framework. Notably, standalone Gemini 3 ranks 3rd here (above Claude Sonnet 4.5), suggesting the base model has latent originality that Creative Brain’s orchestration amplifies dramatically. Gemini 2.5’s elevated RD (129.0) indicates volatile originality performance.
4.3.3 UUU (Unexpected, Useful, Ultra-specific)
| Rank | Player | Rating | RD |
|---|---|---|---|
| 🥇 | Creative Brain (Gemini 3) | 2028 | 107.5 |
| 🥈 | GPT-5 | 1653 | 82.8 |
| 🥉 | Gemini 3 | 1441 | 79.0 |
| 4 | Claude Sonnet 4.5 | 1377 | 78.2 |
| 5 | Gemini 2.5 | 958 | 100.2 |
Table 7: Elo ratings on UUU score. Creative Brain achieves its highest absolute rating (2028) on UUU — a 375-point lead over GPT-5. This framework rewards ideas that are simultaneously surprising and actionable, which aligns with the multi-agent pipeline’s design goal: push for unexpected angles while grounding them in executable detail. Creative Brain’s slightly elevated RD (107.5) suggests occasional variance, but the margin is decisive.
4.4 Cross-framework analysis
The per-framework breakdowns reveal distinct competitive profiles:
| Player | FFE | UOS | UUU | WPP score |
|---|---|---|---|---|
| Creative Brain | 1651 (2nd) | 2006 (1st) | 2028 (1st) | 1889 (1st) |
| GPT-5 | 1895 (1st) | 1657 (2nd) | 1653 (2nd) | 1858 (2nd) |
| Claude Sonnet 4.5 | 1583 (3rd) | 1283 (4th) | 1377 (4th) | 1529 (3rd) |
| Gemini 3 | 1358 (4th) | 1567 (3rd) | 1441 (3rd) | 1169 (4th) |
| Gemini 2.5 | 1285 (5th) | 1009 (5th) | 958 (5th) | 962 (5th) |
Table 8: Aggregate Elo ratings. Key patterns:
- Creative Brain’s advantage is most scores. It ranks 1st on UOS, UUU, and WPP score while it drops to 2nd on FFE.
- GPT-5 is the second best when it comes to creativity. It ranks 1st or 2nd on every single framework. Its weakest showing is 2nd place on UOS, UUU and WPP score, behind Creative Brain.
- Claude Sonnet 4.5 has a spiked profile. Competitive on FFE (3rd, close to Creative Brain), but drops to 4th on UOS and UUU. This suggests its outputs are well-elaborated but less likely to produce unexpected or surprising creative leaps.
- Gemini 3 benefits substantially from the complex orchestration that Creative Brain introduces. Across every framework, Creative Brain outperforms standalone Gemini 3 — the smallest gap is ~293 points (FFE) and the largest is ~720 points (WPP score).
4.5 Rating deviation & confidence
Rating deviation (RD) indicates how confident the system is in each player’s rating — lower RD means more predictable performance and a more stable estimate.
| Player | Avg RD | Min RD | Max RD |
|---|---|---|---|
| Creative Brain | 89.9 | 71.8 (FFE) | 107.5 (UUU) |
| GPT-5 | 86.8 | 82.8 (UUU) | 92.3 (WPP) |
| Claude Sonnet 4.5 | 79.8 | 72.2 (FFE) | 84.7 (UOS) |
| Gemini 3 | 82.3 | 77.8 (FFE) | 90.7 (WPP) |
| Gemini 2.5 | 101.9 | 74.1 (FFE) | 129.0 (UOS) |
Table 9: Mean RD of the LLM players across FFE, UOS, UUU and WPP score ratings. All top-three players converged to RD values below 96 on every framework (with the exception of Creative Brain’s 107.5 on UUU). Gemini 2.5’s RD reaches 129.0 on UOS, indicating that its originality performance is especially unpredictable — consistent with its higher error rate observed during calibration (Section 4.1.1). Claude Sonnet 4.5 has the lowest average RD (79.8), meaning its performance is the most predictable of all players — it reliably delivers a certain quality level even if that ceiling is lower than GPT-5 or Creative Brain on some dimensions.
4.6 Limitations
- Judge model bias. All evaluations were performed using a single LLM as the judge in each scoring sub-agent. While calibrated against human ground truth, any systematic blind spots in the underlying LLM could advantage or disadvantage specific players. Future work should include multi-judge ensembles.
- Prompt parity vs. system parity. Creative Brain receives the same brief as other players but processes it through a multi-agent pipeline — it does more inference work per idea. The tournament tests system-level creative output, not cost-normalised or latency-normalised performance.
- Framework coverage. Semiotics and OSCAI were excluded from per-framework Elo analysis due to high scoring variance (Section 4.3).
- Brief diversity. 14 briefs span a meaningful range of categories but may not cover all creative challenge types (e.g. non-English markets).
- Three iterations. While sufficient for Glicko-2 convergence to low RD in most cases, additional iterations would further tighten confidence intervals.
5. Conclusions
The Creativity Evaluation Agent is deployed and usable via UI and API, and it produces reliable results. The multi-framework approach improves coverage and gives more actionable feedback than a single aggregate score. The path forward includes continued validation against broader and more diverse human panels, expansion of the tournament to track how model capabilities evolve across releases, and integration of the evaluation agent directly into creative workflows — not as a post-hoc judge, but as a real-time collaborator that scores, critiques, and refines ideas within the generation loop itself.

