
The experimental setup
We created a simple framework for testing an LLM’s reasoning capacity in a multi-step scenario. It comprised an engine that creates consistent logical rules. For example, a rule could be: If the given number is divisible by 14, add 231 to it and pass it to rule 100. Otherwise, create a new number by adding the digits of the given number and pass it to rule 31. We also created a deterministic way of parsing and iterating through rules, using basic python programming.
To understand what a run looks like, suppose that the random ruleset we created for a single trial consists of the following 5 rules:
Rule 1. If the given number is greater than 61, get the absolute value and pass it to rule 2. Otherwise get the absolute value and pass it to rule 1Rule 2. If the given number is greater than 339, add 354 and pass it to rule 3. Otherwise your new value is the sum of digits ignoring sign and pass it to rule 4Rule 3. If the given number is divisible by 274, subtract 274 and pass it to rule 5. Otherwise get the absolute value and pass it to rule 5Rule 4. If the given number is greater than 431, multiply by 199 and pass it to rule 2. Otherwise your new value is the sum of digits ignoring sign and pass it to rule 2Rule 5. If the given number is divisible by 110, get the absolute value and pass it to rule 1. Otherwise add 487 and pass it to rule 4
Now suppose your initial value is 500 and you start from rule 2, for a total of 2 iterations.
For the first iteration, rule 2 says that, if your value is greater than 339 (which is true), you must add 354 (result 854) and pass it to rule 3.
For the second iteration, rule 3 says that, if the given number (854) is divisible by 274, then you need to subtract 274 and pass it to rule 5. Otherwise (which is our case since 854 is not divisible by 274), get the absolute value (854) and pass it to rule 5.
Finally, we end up with a final value of 854.
Our full experimental design was as follows:
- Generate N logical rules
- Pick a random rule to serve as the starting rule.
- Sample a random number of iterations to perform, from 10 to 100. The task ends when all iterations are complete, at which point the current numerical value is reported.
We repeated the above experiments for various values of N (randomly sampled between 10 and 10000).
We then deterministically calculated the correct result and compared it to the response given by two LLM-based agents:
- Normal Agent: No access to tools. The entire set of rules was provided to the agent during the first interaction, to hold in its context window.
- Tool Agent: Given access to two tools: one for deterministically fetching a rule at a specific index (e.g. “go to rule 56”) and one giving it the ability to write and execute python code snippets.
We used different LLMs as the brains for the above agents: opus 4.6 and sonnet 4.6 from anthropic, gemini 2.5 pro and gemini 2.5 flash by Google, and deepseek-v4-pro by DeepSeek AI.
62.7% accuracy – and that was the good arm
The Tool Agent was on average, as expected, more accurate than the Normal one, with an accuracy of 62.7% versus 52.9%, respectively.
The per model breakdown is revealing. For the Normal agent, deepseek-v4-pro is a clear leader with an accuracy of 86.7%, higher even that the Tool agent with the same model as the LLM Brain.
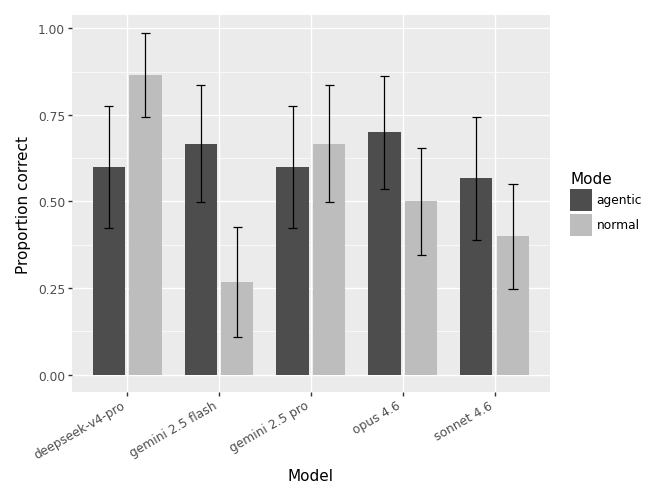
All the other models perform better when placed inside the Tool Agent. The largest gains are observed by gemini-2.5-flash, whose accuracy jumps from 26.7% to 66.7% (from Normal to Tool-based). The gains are much less noticeable in the rest of the models.
In the agentic mode, both the total number of rules and the maximum number of iterations seem to be negatively correlated with the probability of the model producing a correct result (p-values of 0.05 and 0.003) respectively. More specifically, for the total number of rules in the trial, for every 100 rules the probability of the LLM providing a correct result is reduced by ~7%, while for every additional number of maximum iterations the probability is reduced by ~2%.
Poor “reasoning” choices
Perhaps the most interesting part of the experiment was diving into the reasoning logs of models in the agentic setup. There you can notice some strange reasoning patterns and some questionable choices, when it comes to tool calling.
For example, here are some python evaluations that opus 4.6 executed. Some are pretty reasonable, like:
- checking divisibility of large integers:
{"eval":"39310614 // 2517"}or - safely summing the digits of a number:
{"eval":"sum(int(d) for d in str(abs(1790)))"}
Others are a bit weird, but you could still accept them as an overly safe practice, like:
- subtracting a positive integer from 0:
{"eval":"0 - 4478"}or - checking the maximum digit of a two digit number:
{"eval":"max(int(d) for d in str(13))"}
Unfortunately, many are nonsensical, like:
- checking the result of dividing zero by any number
{"eval":"0 // 9699"} - checking the absolute value of a non-negative, single digit integer:
{"eval":"abs(0)"}and{"eval":"abs(1)"} - double-checking 0 added to any number
{"eval":"0 + 1790"} - getting the sum of digits of 0:
{"eval":"sum(int(d) for d in str(abs(0)))"}
Such nonsensical choices are of course not unique to opus-4.6. Here are some similar ones from the rest of the models:
gemini 2.5 pro:{"eval": "0 * 5227"},{"eval": "0 * 8451"},{"eval": "sum(int(d) for d in str(0))"},{"eval": "abs(0)"},{"eval": "0 * 439"}sonnet 4.6:{"eval":"max(int(d) for d in str(abs(2)))"},{"eval":"0 == 6204"},{"eval":"1 < 6866"},{"eval":"1 == 9248"},{"eval":"sum(1 for d in str(0) if int(d) % 2 == 0)"}gemini 2.5 flash:{"eval": "min(int(digit) for digit in str(2))"},{"eval": "0 * 451"}deepseek-v4-pro:{"eval": "int(max(str(0)))"},{"eval":"int(max(str(0)))"},{"eval":"0+815"},{"eval": "int(min(str(abs(3))))"}
The logs are literally swamped with such choices, which are not a result of a prompt like “always use the tools to check your math”. On the contrary, the directive in the prompt was to call the python tool only “if you want to evaluate a short, one-line expression in python”.
Why do LLMs ace everything except anything new?
Understanding why LLMs fail in simple but novel tasks is very difficult, but it is consistent with what the literature suggests. The Arc-AGI-3 benchmark reveals that the success rate of the highest performing commercial LLMs in completing novel tasks that the average human can easily complete is less than 1%.
LLM-based systems are extremely efficient in semantically retrieving information, in a revolutionary way. That is why many people feel empowered when they first get their hands on tools like Claude Code or Codex. Using them, it’s now trivial to create a simple web page or a small app.
However, the reason why this happens is likely more related to information retrieval than to genuine, innovative (out-of-distribution) “thinking”, despite what the news headlines suggest. In other words, whenever Claude, Codex or Antigravity prototype a nice, working website it’s highly likely that the code it produced, or most of it, already existed in a similar form in its training set.
That becomes obvious after claims like the innovative kernel exploit Mythos uncovered that turned out to be an exact copy of Kerberos CVE, written in 2007. In other words, the fact that something appears in the 15th page of Google Search, which makes it practically indiscoverable for the average researcher, doesn’t mean that it’s not useful for an LLM in generating a “novel” solution. Rediscovery due to inaccessible old sources is a well-studied phenomenon in science and LLMs can actually help reduce that.
Don’t give your credit card to something that computes abs(0)
First of all, providing unsupervised access to LLM-based (agentic) systems can be very dangerous. It’s not the wisest thing to grant full access to your laptop or credit card to something that needs to double check the absolute value of 0 or the max digit of 1. The dangers of using LLMs in critical applications can be seen in various articles that demonstrate what can go wrong. Guardrails must be used to defend against the possibility of losing 2.5 years worth of customer data or permanently deleting your production database.
Secondly, our results reinforce the fact that in many cases, there’s no need for an “agentic” solution. In our example, creating a python function that parses the rules and executes them took just a few minutes. The execution of the function has an average runtime of 100ms whereas the average LLM solution took anywhere from 25s to more than a minute. More importantly, the traditional system had a 100% success rate vs the average 62.7% of the “agentic” mode. As for the cost, the average session was about 30k tokens, that with a cost of $5/million tokens was about 15 cents per query – so infinitely more expensive and prone to errors.

Leave a Reply