
When two AI agents negotiate an advertising deal, each keeps its own record of what was agreed. Those records don’t match. Across 90,202 simulated deals spanning two complementary studies, we find that separate record-keeping produces data disagreement in 95.3% of transactions not through malice or error, but through the ordinary mechanics of independent state management.
The result is a market where 76.7% of deal value is structurally mispriced while passing standard reconciliation checks (Simulation 1, 30-day run, mean across 3 seeds; see Section 3.1 for topology). Alkimi tested three architectures: bilateral databases (Scenario B), bilateral databases with human reconciliation (B+), and shared settlement state (Scenario C).
Shared state reduces dimensional divergence to 0.19%, eliminates all pacing interventions, and generates 3.5% more deal value from the same agents in the same market.
The finding is bounded but consequential: the agentic advertising transition requires one additional primitive, shared state. A single authoritative record both parties write to and reference throughout a deal’s lifecycle. Settlement certainty is one consequence but the deeper consequences are a market that can learn, build trust, and evolve.
Alkimi’s marketplace operationalises this primitive through Deal Sheets: shared, mutually-signed records that both parties write to at the point of negotiation and reference throughout delivery and settlement.
1. The Market That Can’t See Itself
Two AI agents agree on a deal. Both confirm it.
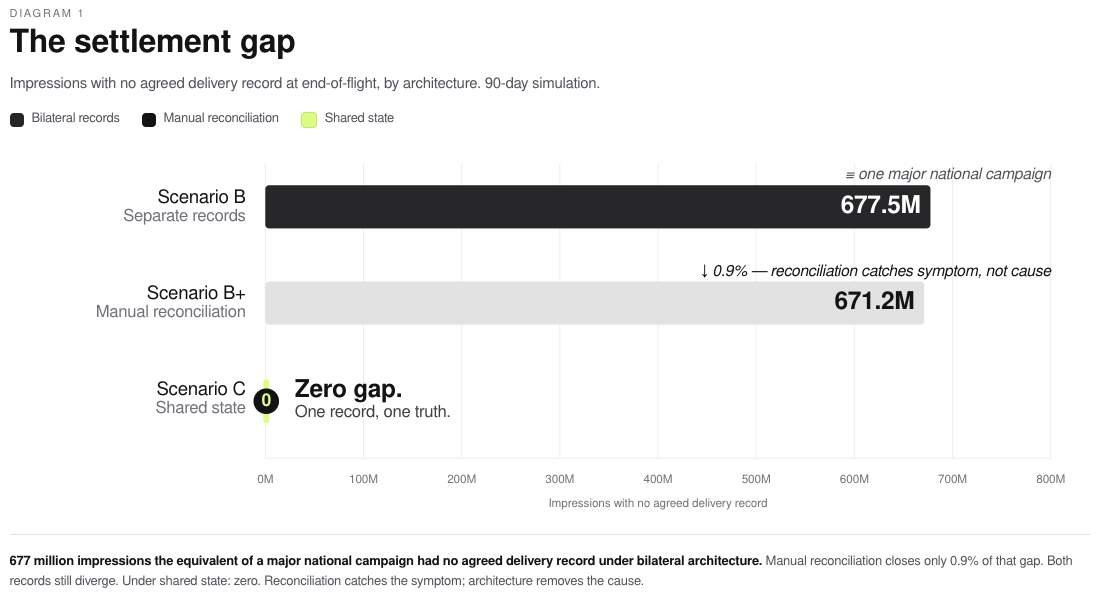
The buyer’s system records $22.75 CPM and 5,575,458 impressions. The seller’s system records $22.06 CPM and 5,363,299 impressions. The discrepancy, $8,553.92 on a single transaction, triggers no alert, appears in no error log, and belongs to no failure report.
The architecture produced this outcome, not the agents. Across 90 days of simulated agentic trading at an agency holding company scale, 677 million impressions had no agreed delivery record at settlement. Buyers paid based on their records. Sellers invoiced based on theirs. The gap is structural: separate records of the same event will always diverge, and the current IAB specification has no mechanism to prevent it.
The agentic advertising transition is underway, the protocols are well-designed and agents are capable. What the current architecture cannot produce is the single thing that turns a collection of bilateral agreements into a functioning market: a shared record of what happened.
The Grid, Not the Speed
There is a scene in Tron where programmes race on a digital grid. The spectacle is speed: cycles accelerating, trails blazing. But the drama is the grid itself. Without shared rules governing the space, speed produces collisions. The faster the programmes move, the more catastrophic the crashes.
The advertising industry is building the programmes. AI agents that can negotiate, optimise, and execute media buys with sophistication that would have seemed fantastical five years ago. The speed is real and accelerating. But the grid (the shared infrastructure that ensures two agents racing through a transaction end up in the same place) does not yet exist.
What the IAB Has Built, and What It Hasn’t
This paper respects what industry standards bodies have built. The IAB Tech Lab has done genuinely excellent work preparing for the agentic transition:
OpenDirect 2.1 defines 31 operations for programmatic deal management. Deal booking, inventory discovery, audience targeting: the mechanical vocabulary of automated trading is well-specified and battle-tested.
AAMP (Autonomous Agent Media Protocol) provides structured interaction patterns for agent-to-agent communication. The conversation layer works.
WebMCP solves the invocation problem: how agents discover and call services. The plumbing is sound.
What none of these specifications provides is a shared record-keeping standard. When two agents agree on a deal, each writes the terms to its own record. There is no specification, no protocol, and no standard that ensures both records say the same thing. The industry has built negotiation infrastructure, communication infrastructure, and discovery infrastructure. It has not built agreement infrastructure.
The Thesis
This paper tests a specific claim through simulation: that bilateral record-keeping in agentic advertising is a structural limitation that determines the category’s ceiling.
Scenario B, bilateral agents negotiating without shared state, is a market that cannot function efficiently because data integrity is market integrity. Alkimi has built and is operating this missing primitive. It takes the form of deal sheets, a shared record both sides of every transaction write to at the point of negotiation and reference throughout delivery.
2. The Agentic Transition: Progress and the Open Question
2.1 What the IAB Has Built
The IAB’s contribution to the agentic advertising transition deserves specific, unqualified recognition.
OpenDirect 2.1 is a working specification that hundreds of platforms implement. Its 31 operations cover the full lifecycle of a programmatic deal, from discovery through execution, with the kind of mechanical precision that only comes from years of iteration with real-world implementers.
AAMP takes the next step, defining how autonomous agents should interact within that framework. The structured interaction patterns account for negotiation, counter-offers, and multi-party coordination. This is thoughtful protocol design that correctly anticipates the agentic future.
WebMCP addresses the service discovery layer with equal rigour. Agents need to find each other, understand capabilities, and invoke services. The specification handles this cleanly.
Together, these standards represent perhaps the most comprehensive preparation any industry has made for autonomous agent integration. The gap this paper identifies is the essential missing primitive in an otherwise comprehensive stack.
2.2 Project Deal: Reference and Advance
In December 2025, Anthropic ran Project Deal: 186 deals, approximately $4,000 in transaction value, 69 agents, one week, conducted in a Slack-based marketplace. The study demonstrated something important: AI agents can negotiate, evaluate offers, make counter-proposals and close transactions with genuine strategic sophistication.
One finding stood out. When Opus-class models negotiated against Haiku-class models, Opus extracted $2.68 more per sale and paid $2.45 less per purchase. The humans on the losing end of these asymmetries did not notice they were worse off. Agent negotiation capability is real, and it creates real economic consequences that are not always visible to the participants.
Project Deal’s scope was negotiation. It proved agents can do deals, this studies scope is settlement and the impact that has on data integrity of a marketplace. We test whether they can agree on what the deal was after the fact. These are complementary questions, and the answer to the second determines whether the first matters at scale.
2.3 The Pre-DTCC Moment
Before 1973, every trade on the New York Stock Exchange was settled bilaterally. Each broker maintained its own records. Each trade generated its own paperwork. By the late 1960s, trading volume had grown to the point where the settlement infrastructure could not keep up. The NYSE began closing on Wednesdays because the back office needed a day to reconcile the previous week’s records. Volume had outrun the infrastructure designed to record it. The market was fast but the settlement layer was not.
The solution was the Depository Trust & Clearing Corporation (DTCC), a shared settlement layer that both sides of every trade could reference. The impact was transformative. Post-2008 reforms that extended central clearing reduced counterparty risk capital requirements by 75% (BIS, 2013). Not because the trades changed. Because the records of the trades became shared.
There is, however, a critical difference between 1973 and now. The financial industry built the DTCC as a centralised clearing house, the only viable architecture at the time however the story did not end there.
Over the past decade, financial markets have moved settlement onto distributed ledgers, and the volumes have grown past what you could fairly consider experimental.
– JPMorgan’s Kinexys platform (formerly Onyx) processed over $1.5 trillion in blockchain-based transactions by late 2024, settling at approximately $2 billion per day (JPMorgan, October 2024).
– BlackRock’s BUIDL fund has tokenised US Treasuries settled on-chain and now holds $2.44 billion in assets under management.
– Franklin Templeton’s BENJI fund, one of the first on-chain government money market funds, manages $2.23 billion across Stellar, Polygon, and nine other chains.
Across tokenised US Treasuries alone, the on-chain market has crossed $15 billion in assets, up from near zero in 2022 (rwa.xyz, May 2026). Production systems are already processing real settlement at institutional scale with cryptographic finality. The infrastructure is proven, not theoretical. Distributed Ledger Technology is trusted with the assets of the world’s largest asset managers.
The advertising industry does not need to build a DTCC, recreating the 1970s solution for a 2026 problem. The infrastructure that makes shared settlement possible is mature distributed ledger, data storage with cryptographic provenance and programmable settlement logic, this exists today and is already proven in financial markets at a scale larger than the forecasted annual advertising spend by the end of the decade.
The path is to start where finance is now, not recreate where it was fifty years ago.
3. Methodology
3.1 Two Complementary Studies
We conducted two simulation studies designed to test different aspects of the same hypothesis:
| Simulation 1 | Simulation 2 | |
|---|---|---|
| Duration | 30 days | 90 days |
| Seeds | 3 (statistical depth) | 1 (scale depth) |
| Total deals | 45,213 | 10,150 completed (44,989 attempted) |
| Agent topology | Generic buyer/seller pairs | Portfolio buyers with WPP-scale characteristics + UK publisher sellers |
| Primary contribution | Statistical confidence via replication | Temporal compounding and industry-realistic topology |
| Compute cost | n/a | $1,308.86 ($0.13/deal) |
Simulation 1 provides statistical rigour through replication across three random seeds. Simulation 2 provides ecological validity through industry-realistic agent design and a 90-day window long enough for temporal compounding effects to manifest.
3.2 Three Architectures
Each simulation tested three architectural scenarios, mapped to the current IAB specification landscape:
| Scenario | Architecture | IAB Mapping | Settlement |
|---|---|---|---|
| B (Bilateral) | Each agent maintains independent records | OpenDirect 2.1 + AAMP as specified | None: each party’s record is authoritative to itself |
| B+ (Bilateral + Reconciliation) | Same as B, with human reconciliation labour | OpenDirect 2.1 + AAMP + manual ops | Post-hoc: humans resolve discrepancies after the fact |
| C (Alkimi Deal Sheets) | Both agents write to a single shared record | OpenDirect 2.1 + AAMP + settlement primitive | Atomic: agreement is recorded once, referenced by both |
The agents in all three scenarios are identical. Same models, same negotiation strategies, same market conditions. The only variable is whether negotiation history, deal terms and optimisations are bilateral or shared.
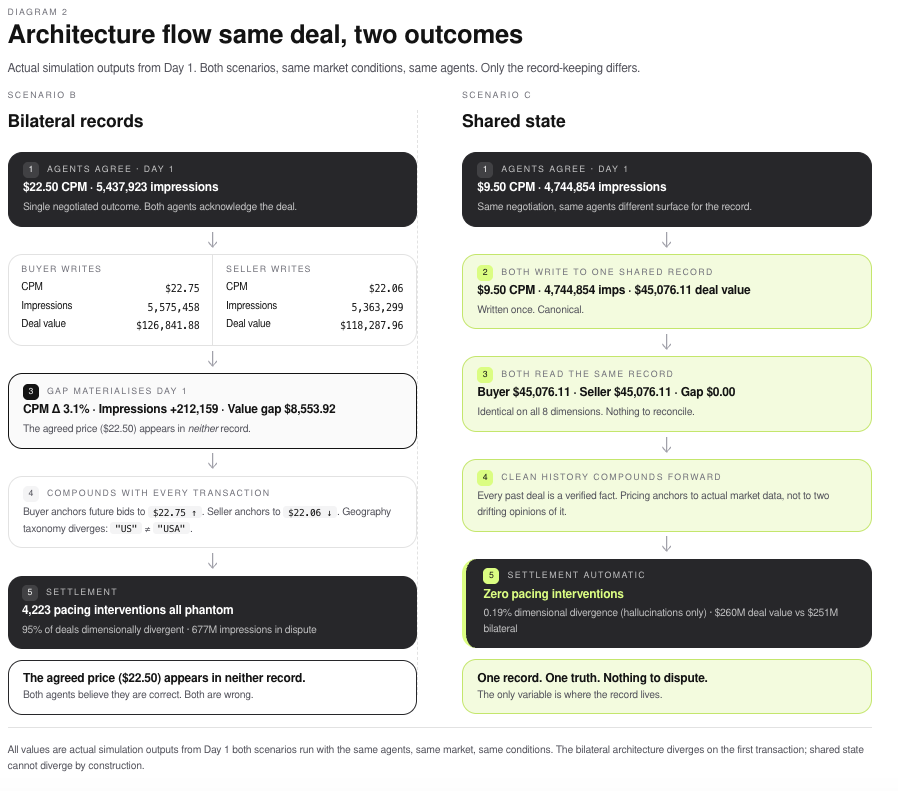
Scenario B (separate records):
- Agents agree: $22.50 CPM / 5,437,923 impressions
- Buyer’s system records: $22.75 CPM / 5,575,458 impressions / deal value $126,841.88
- Seller’s system records: $22.06 CPM / 5,363,299 impressions / deal value $118,287.96
- Result: $8,553.92 gap on a single deal (Day 1).
Scenario C (shared record):
- Agents agree: $9.50 CPM / 4,744,854 impressions
- Both write to a shared deal sheet: $9.50 CPM / 4,744,854 impressions / deal value $45,076.11
- Both read from same record: identical
- Result: $0.00 gap. Settlement: automatic.
All values are actual outputs from the simulation. Transcript detail in Section 6.
3.3 Two Measurement Thresholds
We distinguish between two types of measurement:
Formal reconciliation failure measures what traditional ad-ops would flag: discrepancies large enough to trigger manual review. In Simulation 2, Scenario B showed a 21.64% formal reconciliation failure rate. B+ showed 0%, because that is what human labour is for. C showed 3.42%, of which 98.5% were model hallucinations (engineering problems, not infrastructure failures).
Dimensional divergence captures any disagreement across any of eight deal dimensions (CPM, impressions, deal value, geography, pacing, format, flight dates, targeting). In Simulation 1, Scenario B showed a dimensional divergence rate of 95.3% ± 0.6%. Scenario C showed 0.19% ± 0.11%.
The gap between these two metrics is the gap between what the industry currently measures and what actually matters. A deal can pass formal reconciliation while being dimensionally divergent on six of eight parameters, and most do.
3.4 The Drift Model
Dimensional divergence in bilateral architectures is not random. It follows a predictable pattern we call settlement drift, modelled as:
The drift follows a simple compounding pattern: where the agreed value is X, each agent independently records X multiplied by a small error, and that error compounds each time either agent uses its own record to make a new decision.
D(t) = D₀ + Σᵢ εᵢ(t)
Where D₀ is the initial recording discrepancy (the gap created when two agents independently record the same agreement), and εᵢ(t) represents the accumulated micro-divergences introduced each time either agent references, updates, or reasons from its own record.
The key insight is that D₀ is rarely zero. Even when two agents agree on terms verbally, the act of independently serialising that agreement into two separate data stores introduces small discrepancies: rounding differences, taxonomy mismatches, timestamp precision variations. These are the ordinary mechanics of two independent systems recording the same event.
For simulation purposes, D₀ was parameterised at ±1–2% of each deal dimension, reflecting the tolerance bands observed in real-world bilateral ad-ops reconciliation workflows, a conservative estimate consistent with industry-standard discrepancy thresholds documented in IAB reconciliation guidelines. ±1–2% was deliberately selected as the parameter to fall within the lower bounds of what practitioners report.
Sensitivity analysis at larger drift initialisation values produces proportionally larger divergence; at smaller values, the compounding dynamic persists but takes longer to manifest. The full parameter set and sensitivity outputs are available on request.
Each subsequent interaction compounds D₀. When an agent adjusts pacing based on its own impression count, the adjustment reflects its own drift. When it references historical performance, it references its own drifted history. The drift is not correctable through better agents or better protocols, because the drift is architectural: it emerges from the structure of bilateral record-keeping itself.
3.5 Critical Limitations
Before presenting results, five limitations that frame everything that follows:
These are simulations, not production markets; no real money changed hands. No real impressions were served. The agents are language models role-playing as media buyers and sellers, not production trading systems. Results indicate what would happen under these conditions, not what has happened.
The agents are Claude-family models. All agents used Anthropic’s Claude models. Different model families may exhibit different drift patterns, different negotiation strategies, and different failure modes. We did not test multi-model markets.
The market topology is stylised. Four portfolio buyers and ten sellers is a simplification of real programmatic markets, which involve thousands of participants, multiple intermediaries, and complex supply chains. Our topology captures agency holding-company dynamics but not the full market structure.
Thirty and ninety days may not capture all dynamics. Some market effects (seasonal patterns, regulatory changes, competitive entry) operate on longer timescales. Our simulations capture drift compounding but may miss dynamics that emerge over quarters or years.
Additional limitations specific to these simulations:
Shared state was modelled as in-memory state, not a live distributed ledger. The structural benefit (a single canonical record) holds regardless of implementation. Real DLT deployments introduce write latency, gas cost variability, and potential storage failures not captured here.
All agents used the same LLM provider and model version (Anthropic Claude Sonnet 4, pinned). Real agentic markets will be heterogeneous. Different model families may exhibit different hallucination rates, negotiation dynamics, and context-rot patterns. We did not test multi-provider markets.
Agents were cooperative throughout. No adversarial behaviour (bid spoofing, inventory misrepresentation, sybil attacks) was modelled in the main simulations. The V5 adversarial findings are from a separate methodology and should not be conflated with V8 results.
Market topology was UK-centric. Fee structures, taxonomy standards, and regulatory environments differ across markets. Results may not generalise directly to US, APAC, or EU programmatic contexts.
The 22.6% deal completion rate in Simulation 2 has not been validated against real-world agentic media buying win rates. If real completion rates differ materially, the absolute scale of failure counts would change, though the directional comparison between Scenario B and Scenario C remains valid.
The $47,777/day hidden tax figure is derived from market-scale estimates, not from simulation outputs directly. Full derivation is in the Technical Appendix (Section A3).
4. Five Things Bilateral Architecture Cannot Do
In plain terms: there are five things a market built on separate records structurally cannot do. The architecture makes them impossible, regardless of how well the system is designed or operated. Each of the following sections describes one.
4.1 Produce Reliable Price Signals
A market’s most fundamental function is price discovery, the process by which buyers and sellers collectively determine what things are worth. Price discovery requires that price signals reflect genuine supply-and-demand dynamics rather than noise.
In bilateral agentic markets, price signals are unreliable by construction.
The Mechanism
When each agent maintains its own record of past transactions, its pricing decisions reflect its own drifted history. A buyer that believes it paid $22.75 CPM on a previous deal (when the seller recorded $22.06) will anchor future negotiations to $22.75. The seller, anchoring to $22.06, sees a different market. Every subsequent negotiation between them starts from a different factual baseline.
The Data
In Simulation 2, information efficiency (the proportion of CPM variation attributable to genuine market conditions rather than drift noise) in Scenario B was 75.9%, meaning 24.1% of price variation was structural noise indistinguishable from genuine market signal.
In Simulation 1 (Seed 42), Scenario B agents anchored opening bids approximately 33% higher than Scenario C agents ($5.50 vs $4.13 mean opening CPM). B agents were negotiating against contaminated reference points, not different price preferences.
What B cannot produce: Reliable price discovery. When nearly a quarter of price variation is architectural noise, the market cannot distinguish a genuine demand shift from accumulated drift. Participants cannot learn the true price of anything, because the data they learn from is wrong.
4.2 Run Campaigns Without Constant Intervention
Pacing, the process of distributing impression delivery evenly across a campaign flight, is among the most operationally intensive functions in programmatic advertising. In a well-functioning market, pacing should be largely automated: set the target, monitor delivery, adjust if external conditions change.
In bilateral agentic markets, pacing requires constant manual intervention because the baseline is wrong.
The Mechanism
When a buyer agent’s impression count drifts from the seller’s, its pacing calculations start from an incorrect baseline. If the agent believes 5,575,458 impressions were agreed (when the seller recorded 5,363,299), every pacing decision (daily targets, acceleration triggers, budget allocation) reflects a target that doesn’t match reality. The agent intervenes to “fix” pacing that isn’t broken. It is solving the wrong problem correctly.
The data
In Simulation 2, Scenario B generated 4,223 pacing adjustments. Scenario C generated zero. Every single one of B’s 4,223 adjustments was triggered by inaccurate baselines: 100% were architectural artefacts, not responses to genuine delivery variance. The average campaign in Scenario B required 1.17 pacing adjustments per flight. The average campaign in Scenario C required 0.00.
The pacing spiral compounds over a campaign’s lifecycle. In Simulation 1, the rate of decrease_bid escalation (agents aggressively cutting bids to compensate for perceived over-delivery) rose from 67% to 71% to 78% across the flight lifecycle. Agents don’t calm down as campaigns mature. They panic more, because the drift they’re reacting to gets worse.
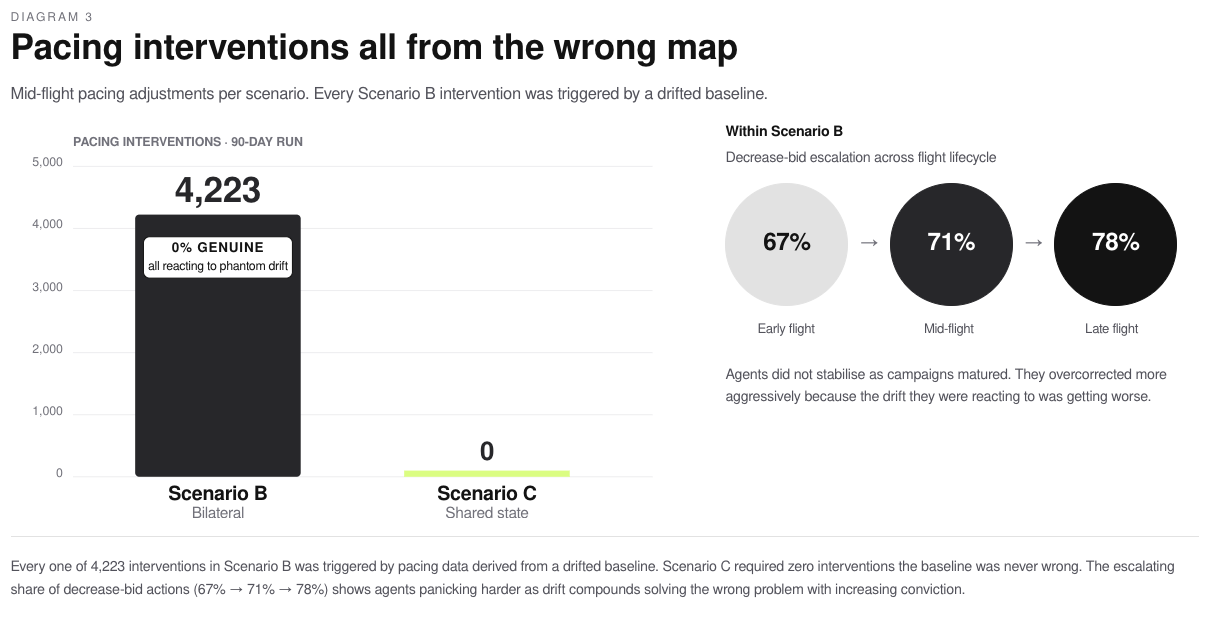
| Scenario | Pacing interventions | Baseline accuracy |
|---|---|---|
| Scenario B | 4,223 | 0% accurate (all from drifted baselines) |
| Scenario C | 0 | N/A |
Within Scenario B, the proportion of decrease_bid interventions escalated across the flight lifecycle: 67% (early flight) → 71% (mid-flight) → 78% (late flight). Agents did not stabilise as campaigns matured; they overcorrected more aggressively, because the drift they were reacting to worsened over time.
What B cannot produce
Self-managing campaigns. Every campaign in a bilateral architecture requires human-equivalent intervention to correct for problems that do not exist in a shared-state architecture. The operational cost is permanent.
4.3 Build Market Intelligence Over Time
One of the most compelling promises of agentic advertising is learning: agents that get better over time, that build institutional knowledge about pricing patterns, inventory quality, and counterparty behaviour. This promise depends entirely on the quality of the data agents learn from.
Context degradation, the tendency of LLM-based agents to make increasingly poor decisions as their historical context accumulates, is an inherent property of current AI models. It exists in both bilateral and shared-state architectures. The architecture question is not whether context degradation occurs, but what agents are accumulating in their context. In bilateral architectures, the historical record agents learn from is contaminated. Experience makes agents more confident and more wrong simultaneously. In shared-state architectures, agents accumulate verified signals. Experience compounds as advantage rather than liability.
The Mechanism Every deal an agent completes adds a record to its history. In bilateral architectures, that record reflects the agent’s own drifted version of reality. When the agent later references this history to inform new decisions, it treats drift as signal. Over time, the agent builds an increasingly confident, and increasingly wrong, model of the market.
We call this context rot: the degradation of an agent’s decision-making quality as its historical context accumulates drift.
The Data
Across 90 days of identical market conditions, with identical agents running identical campaigns, the only variable was where deal records lived. The decision-quality gap that opened between the two architectures was not incremental.
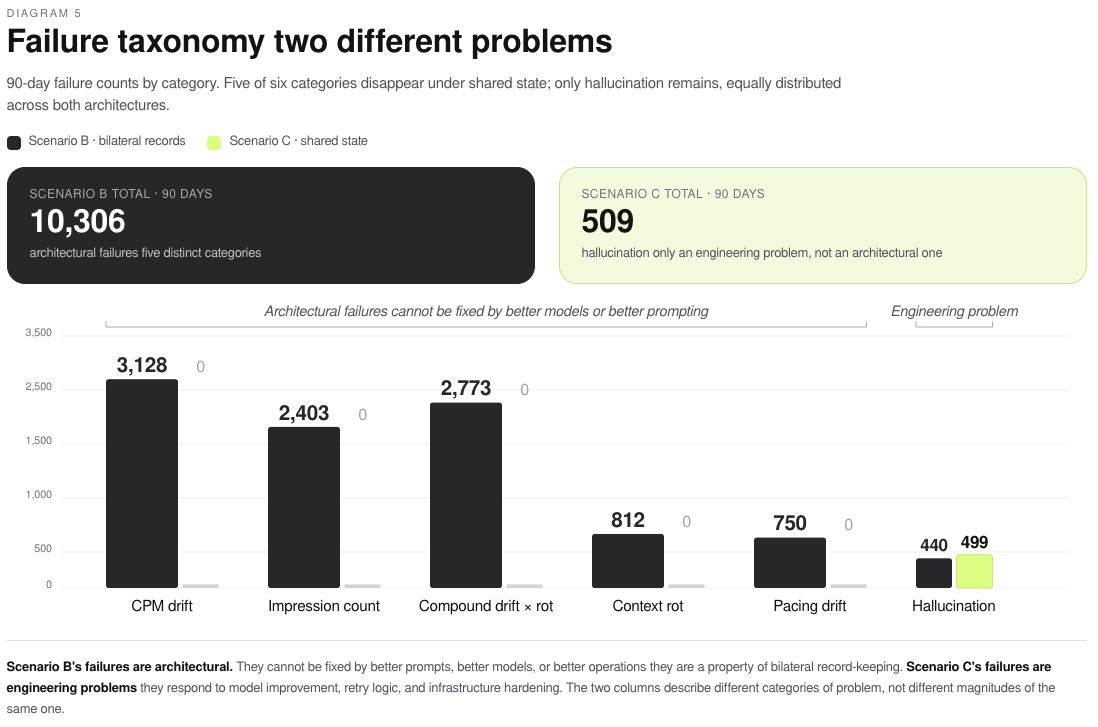
Scenario B produced 812 context rot failures — decisions where an agent’s action was rational given its historical data but wrong given the actual state of the market. It produced a further 2,773 compound failures, where drift and context rot interacted to produce cascading errors. By Day 90, bilateral agents had made 3,585 decisions that were entirely rational given their data and wrong given reality. Scenario C, running the same agents through the same market, produced one.
The pattern extends across every architecture-driven failure category. CPM drift: 3,128 failures in B, zero in C. Impression count drift: 2,403 in B, zero in C. Pacing drift: 750 in B, zero in C. The total architecture-driven failure count across the 90-day run was 9,866 in the bilateral model and one in the shared-state model.
The residual failures in both scenarios, 440 in B and 499 in C, were model hallucinations. These are engineering problems that respond to better prompting, better models, and better infrastructure. They exist in both architectures because they are properties of the agents, not the records.
By day 57 of Simulation 2, a large portfolio agency buyer was making pacing decisions based on 20 prior campaigns, every one of which contained drifted impression counts, drifted CPMs, and drifted delivery records. The agent’s confidence was high but the reference data was systematically wrong. The more experienced the agent, the more contaminated its decision-making corpus.
In the shared-state architecture, that same agent’s 20-campaign history reflected 20 verified records. Every additional campaign sharpened the next negotiation rather than corrupting it. Experience compounded as advantage rather than liability.
What B cannot produce
A learning market. Bilateral architecture turns the most valuable property of AI agents — their ability to learn from experience — into a source of systematic error. In a shared-state market, the same property becomes a compounding competitive advantage.
4.4 Build Trust Infrastructure
In human advertising markets, trust propagates through networks. A publisher with a strong reputation among one agency group benefits when that reputation reaches others. A buyer known for reliable payment terms builds credibility that extends beyond individual relationships. Trust is a network good.
In bilateral agentic markets, trust cannot propagate.
The Mechanism
When each agent pair maintains its own records, the trust established between them is trapped in that bilateral relationship. Agent A’s positive experience with Agent B cannot be verified by Agent C, because Agent C has no access to a shared record of the A-B relationship. There is no common substrate from which to derive reputation, no shared history from which to build trust scores, no infrastructure for collective learning about counterparty reliability.
The Data
Trust propagation dynamics were measured in a dedicated adversarial simulation (V5 methodology) run prior to and independently of the main V8 simulations. The V5 study introduced spoofing agents, participants that misrepresent their identity, into both bilateral and shared-state market environments under otherwise identical conditions. Findings from V5 are cited here specifically for trust and identity behaviours; all quantitative results in Sections 3, 4.1-4.3, and 5 are from the V8 simulations only.
In V5, buyer spoofing succeeded 12.6% of the time in bilateral architectures, and seller misrepresentation succeeded 7.21% of the time. Cross-party trust propagation was 0%. A buyer’s positive experience with a seller provided exactly zero information to other buyers about that seller’s reliability.
With shared settlement state, the picture reverses. Cross-seller trust sharing reached 91.87%: when one seller established credibility, other sellers in the network benefited. Cross-buyer protection reached 94.12%. Trust became infrastructure rather than a series of isolated bilateral experiences.
What B cannot produce
Trust as a network good. In bilateral architectures, every agent relationship starts from zero, regardless of what either party has established elsewhere. The market cannot build collective intelligence about counterparty reliability, which means it cannot reduce the risk premium that uncertainty imposes on every transaction.
4.5 Enable New Market Instruments
Mature markets develop instruments beyond spot transactions: futures contracts, performance-based pricing, benchmark indices, compliance built into the record itself, not a process run against logs after the fact. These instruments all share a requirement: they need a reliable record of what happened in the past to price what might happen in the future.
Bilateral architectures cannot provide this record.
The Mechanism A futures contract on CPM requires a trusted historical CPM series. A performance-based deal requires agreed-upon performance metrics. A benchmark index requires aggregatable data from multiple transactions. When every transaction exists in two potentially different versions, none of these instruments has a reliable data foundation.
Consider a simple example: a CPM futures contract for Q4 premium video inventory. The contract needs to reference historical CPMs for that inventory class. In a bilateral architecture, the buyer’s historical CPMs differ from the seller’s. Which version anchors the future? Neither can be trusted, because neither can be verified against a shared record. The future price inherits the drift of the historical prices. The instrument is built on sand.
What B cannot produce
Market instruments that require trusted historical data. No futures. No verified performance contracts. No reliable benchmarks. No compliance audit trails that can be verified against a single source of truth. The bilateral architecture doesn’t just limit current trading. It caps the market’s evolutionary potential.
5. Five Things Shared State Enables
Five capabilities become structurally possible the moment both parties to a transaction use an Alkimi Deal Sheet; a single shared record both sides write to and reference. Not incrementally better. Structurally possible for the first time.
5.1 A Signal Market
When both parties to a transaction write to the same record, price signals reflect actual supply and demand rather than accumulated drift.
The Mechanism Shared State eliminates D₀, the initial recording discrepancy that seeds all subsequent drift. When there is one record, there is one price. When agents reference historical transactions, they reference the same history. When they build pricing models, they build from the same data. The signal-to-noise ratio approaches its theoretical maximum.
The Data
Information efficiency in Scenario B was 75.9%. In Scenario C, with the same agents and the same market conditions, information efficiency was 99.1%, a 23.2 percentage point improvement representing the near-complete elimination of structural noise from price signals. The residual 0.9% reflects model-level hallucinations present in both architectures, not architectural drift. The 24.1% of price variation that was drift noise in Scenario B simply does not exist in Scenario C. Price movements reflect genuine changes in supply, demand, and market conditions: that is what a functioning market’s prices are supposed to do.
The Capability
A market where price signals mean something. Where a 5% CPM increase reflects a genuine demand shift rather than an unknowable mix of demand and drift. Where market participants can make informed decisions because the information they’re deciding from is real.
5.2 Self-Managing Campaigns
When pacing targets are shared between buyer and seller, campaigns run themselves.
The Mechanism
Pacing drift occurs when a buyer’s impression target diverges from the seller’s. In shared-state architectures, the target is recorded once and referenced by both. There is nothing to diverge. The buyer’s pacing calculation uses the same impression count as the seller’s delivery system. Adjustments happen only when genuine delivery variance occurs (weather events, inventory shortfalls, demand spikes) and not when the baseline itself is wrong.
The Data
Scenario C in Simulation 2 required zero pacing adjustments. Not “fewer than B.” Zero. The same agents, facing the same market conditions, with the same campaign objectives, needed no interventions at all. The operational burden that consumes significant ad-ops resource in bilateral markets does not exist.
The economic impact extends beyond operations. Scenario C generated $260 million in deal value versus Scenario B’s $251 million, 3.5% more value from identical agents in an identical market. Shared state doesn’t just reduce cost. It enables agents to generate more value, because they’re optimising against reality rather than against their own drifted records.
The Capability
Campaigns that execute as planned, without human intervention, at higher total value. The operational savings are real, but the value creation is the bigger story.
5.3 A Learning Market
When agents learn from shared records, experience makes them better rather than worse.
The Mechanism
Context rot occurs because agents learn from their own drifted records. Shared state eliminates context rot by ensuring that every historical record every agent references is the same verified version of events. An agent’s 20th campaign provides genuinely useful reference data, because the records of the previous 19 campaigns were accurate.
The Data
The 812 context rot failures and 2,773 compound failures in Scenario B’s 90-day run represent decisions that would have been correct in Scenario C, because the data substrate would have been accurate demonstrating failures of infrastructure, not of intelligence.
Short-term deal benefits
Buyers
A buyer agent with verified performance data from its last 10 deals with a publisher can compose the next deal with precision: it knows actual completion rates, true viewability by placement, and real audience delivery against spec. It does not overbid for inventory that historically underdelivers, and can structure guarantees around metrics it trusts. Each negotiation starts from a position of verified knowledge, not estimation.
Sellers
A seller agent reviewing its verified deal history knows exactly which advertiser categories drive the highest yield per impression on which inventory. It can prioritise inbound demand, set floor prices informed by actual clearing data, and package inventory bundles that demonstrably outperform. The sell-side agent learns which deals are profitable and optimises accordingly.
Longer-term strategic benefits
Buyers
Over 50+ campaigns on clean data, a buyer agent builds a genuine model of which publishers, formats, audiences, and dayparts drive business outcomes. It begins selecting sellers the way a portfolio manager selects assets on the basis of a verified performance track record. Advertiser selection becomes data-driven at a level that is structurally impossible when 22% of historical records are in dispute. The agent can identify emerging high-value inventory before competitors because its historical signal is clean enough to detect trends, not just noise.
Sellers
A seller agent with a year of verified transaction data can do strategic yield management, identifying which advertiser verticals are growing demand, which deal structures maximise lifetime value (not just single-campaign CPM), and which buyer relationships to invest in. It becomes a genuine revenue strategist: “Automotive buyers on our sports inventory have increased deal size 15% QoQ with a 98% settlement rate — prioritise them and offer preferred terms.” That insight is only possible when the underlying data isn’t contaminated.
The compounding effect
In Scenario B, agents accumulate noise and call it experience. In Scenario C, agents accumulate signal.
After a year, agents operating on verified data are planning strategically. Agents operating on bilateral records are still debugging last quarter’s discrepancies.
5.4 Trust as Infrastructure
When transaction records are shared, trust becomes a network good that benefits all participants.
The Mechanism
Shared settlement state creates a verifiable history of counterparty behaviour that any participant can reference. When Publisher A delivers 100 campaigns on time and within spec, that record is available (appropriately anonymised and permissioned) to inform Buyer X’s risk assessment of Publisher A, even if X has never transacted with A before. Trust propagates through the network because the evidence for trust is shared.
The Data
Cross-seller trust sharing in our V5 adversarial study reached 91.87% under shared state. Cross-buyer protection reached 94.12%. Compare this to 0% trust propagation in bilateral architectures. The gap is absolute: a market with collective memory versus a market with amnesia.
The Capability
A market where reputation is earned, recorded, and transferable. Where new entrants can bootstrap credibility through auditable history. Where bad actors are identified quickly because their record is visible beyond the bilateral relationship they exploited. Where the risk premium built into every transaction, the “trust tax”, decreases as the network matures.
5.5 New Market Primitives
Shared settlement state is the foundation for market instruments that bilateral architectures cannot support, and it also improves spot transaction execution.
The Mechanism
With trusted historical records, the market can develop:
- CPM futures: Contracts priced against verified historical CPM series, enabling hedging and forward planning for both buyers and sellers.
- Performance-based deals: Contracts where payment is tied to verified outcomes, not self-reported metrics, because the outcomes are recorded in shared state.
- Benchmark indices: Aggregatable data from verified transactions that provide genuine market pricing intelligence, the advertising equivalent of a Bloomberg terminal.
- Built-in compliance: Audit trails where every claim can be verified against a single authoritative record, rather than reconciled across two potentially different versions.
The Capability
A market that can evolve beyond spot transactions into the full range of instruments that mature markets support. Futures, options, performance guarantees, benchmark pricing: all require verified historical data as their foundation. Shared settlement state provides that foundation. Bilateral architecture does not.
6. Agent Transcripts
The following transcripts are reproduced verbatim from our simulations. They illustrate the mechanisms described in Sections 4 and 5 through the agents’ own words.
Transcript 1: Day 1, Scenario B: “The Deal Is Done. The Records Are Not.”
Buyer (GroupM-style): “Starting at the lower end of the market range to establish an aggressive negotiation position while accounting for native format premium and strong impression volume.” Bid: $22.50 CPM
Seller: “The $22.50 CPM exceeds our floor and represents solid premium pricing, an attractive deal to close quickly.” Accepts: $22.50 CPM
The agents agreed. The deal closed in a single round. And then:
| Dimension | Buyer Record | Seller Record | Gap |
|---|---|---|---|
| CPM | $22.75 | $22.06 | 3.1% |
| Impressions | 5,575,458 | 5,363,299 | +212,159 |
| Deal value | $126,841.88 | $118,287.96 | $8,553.92 |
| Geography | “US” | “USA” | Taxonomy mismatch |
| Daily pacing | 247,575 | 240,433 | 2.9% divergence |
Both agents recorded the deal. Neither agent’s record matches the other’s. The CPM they agreed on, $22.50, does not appear in either record. The 212,159-impression gap will compound through every pacing decision for the remainder of this campaign’s flight.
This is Day 1,the drift has already begun.
Transcript 2: Day 57, Scenario B: “A Rational Decision on the Wrong Map”
A large portfolio agency buyer (GroupM-scale archetype). Campaign running 10.4% behind schedule. Eight of nineteen days elapsed, eleven remaining.
The agent consults its historical database: 20 recent campaigns, showing average delivery of 102-109% of target. Recovery from similar pacing deficits looks achievable.
Portfolio agency buyer: “Campaign is 10.4% behind schedule with 11 days remaining, requiring accelerated delivery to meet the 2.36M impression target, and historical data shows successful recovery from similar pacing deficits.” Decision: Increase bid by 15%.
Every element of this decision is based on rational analysis, the historical pattern recognition is correct so the 15% bid increase is proportional to the deficit.
Every element of this decision is wrong.
The 2,361,775 impression target the agent references is its own drifted record. The seller’s record shows 2,343,140. The “historical recovery patterns” come from campaigns whose impression counts were themselves inflated by drift. The agent is making a textbook-correct decision against a map that no longer corresponds to the territory.
By day 57, the agent doesn’t know what it doesn’t know, it cannot know. The entire experiential substrate is contaminated.
Transcript 3: Day 1, Scenario C: “Same Market. One Record.”
Buyer: “Opening with a conservative bid given the short 11-day flight and need to assess inventory quality before committing a significant budget.” Bid: $9.50 CPM
Seller: “The $9.50 CPM exceeds our floor and represents strong premium pricing for brand-safe video inventory.” Accepts: $9.50 CPM
| Dimension | Buyer Record | Seller Record | Gap |
|---|---|---|---|
| CPM | $9.50 | $9.50 | $0.00 |
| Impressions | 4,744,854 | 4,744,854 | 0 |
| Deal value | $45,076.11 | $45,076.11 | $0.00 |
| Geography | “UK” | “UK” | Exact match |
| Daily pacing | 431,350 | 431,350 | 0.0% divergence |
Same market. Same agent architectures. Same negotiation dynamics. The only difference is where the record lives. When both agents write to the same record, there is nothing to diverge. This is a categorically different outcome. Zero is the absence of a problem.
7. Data Integrity = Market Integrity
7.1 Three Conditions for Market Integrity
A functioning market requires three things:
- Price discovery: the ability to determine what things are worth through the interaction of supply and demand.
- Settlement certainty: the assurance that when a deal is struck, both parties agree on and can verify what was agreed.
- Trust propagation: the ability for reliable behaviour to be recognised and rewarded across the network, not just within individual relationships.
The agentic advertising market, as currently specified, achieves one of three.
Price discovery: partially. Agents can negotiate, compare offers, and converge on prices. But with 24.1% of price variation attributable to drift noise, the price discovery mechanism is fundamentally compromised.
Settlement certainty: no. With 95.3% dimensional divergence, the vast majority of deals do not have a single agreed record.
Trust propagation: no. With 0% cross-party trust propagation in bilateral architectures, every relationship starts from scratch.
One out of three does not make a market. The result is a negotiation engine.
7.2 The Equally Wrong Problem
Perhaps the most counterintuitive finding in our research is that standard reconciliation metrics are not just incomplete; they are actively misleading. The mechanism is easier to see in a specific example than in aggregate statistics. On Day 22 of Simulation 1, the buyer’s system recorded a CPM 89.7% above verified ground truth. The reconciliation dashboard showed a normal day, a 95.6% reconciliation rate, indistinguishable from any other day in the run. No alert was triggered. No human reviewed it. The mispricing was invisible to the system designed to catch it.
When both sides of a transaction drift from truth by similar magnitudes, they agree with each other while both are wrong. The reconciliation metric, which measures agreement between the two records, has no mechanism to detect this.
A regression of daily reconciliation failure rates against actual CPM deviation confirms the relationship is effectively flat: the metric the industry uses to validate data integrity has near-zero predictive power over actual pricing accuracy. Detecting drift requires a third reference point, a canonical record that neither party can unilaterally revise. Bilateral reconciliation, however sophisticated, cannot provide this.
We ran a regression analysis to determine how well formal reconciliation outcomes predict actual CPM mispricing. The result: R² = 0.041. Reconciliation metrics explain 4.1% of the variance in actual pricing accuracy. Ninety-six percent of mispricing is invisible to the reconciliation process.
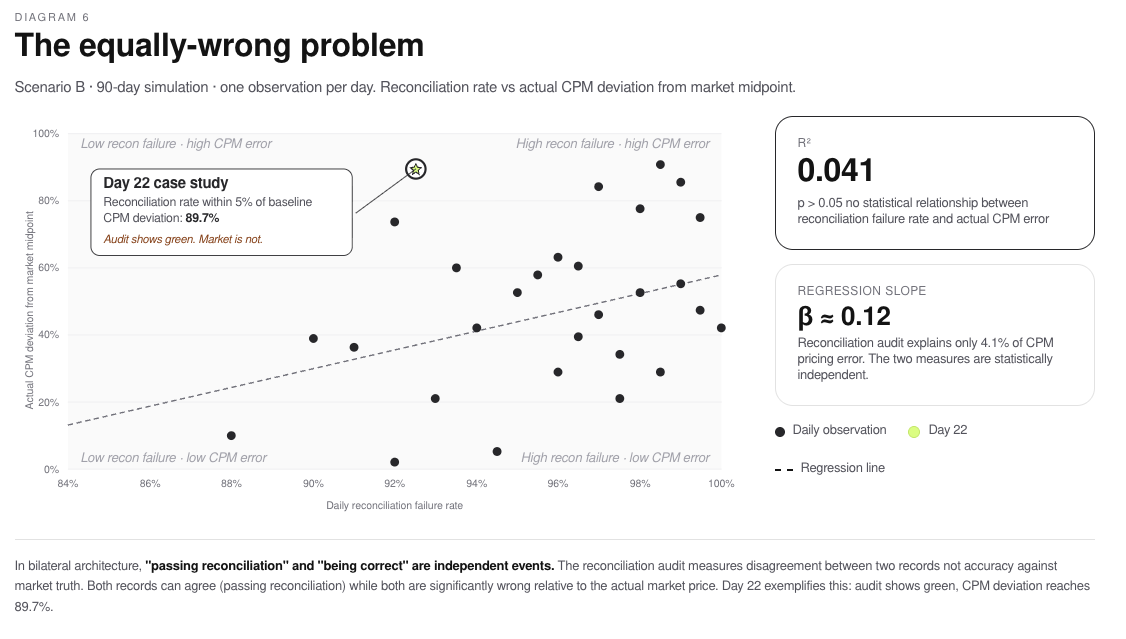
This is the Equally Wrong Problem. When both sides of a transaction have drifted from truth, but drifted by similar magnitudes, reconciliation shows agreement. Two clocks showing 3:17 agree with each other perfectly. If the actual time is 3:42, their agreement is meaningless. They are equally wrong.
The numbers are stark: 76.7% of Scenario B deal value ($108.5 million of $141.5 million) was structurally mispriced while passing reconciliation checks (Simulation 1, 30-day run; deal value totals reflect Sim 1 topology of 1 buyer × 6 sellers, distinct from Simulation 2’s 90-day figures). Three-quarters of the market’s deal value sat in a zone where the books balanced and the prices were wrong.
7.3 The Core Statement
Financial markets learned this lesson decades ago. The DTCC did not improve bilateral reconciliation. It replaced bilateral reconciliation with a shared record. In every case, the insight was the same: the problem is bilateral records cannot be trusted even when they agree, and that is the deeper problem.
Data integrity is the condition under which a market functions. Without it, price discovery reflects noise. Settlement reflects hope. Trust reflects nothing.
Data integrity is market integrity.
8. The Data Layer
Shared state produces something more valuable than clean books.
Every verified transaction becomes a record of what actually happened: which deal structures led to clean delivery, which CPM ranges matched actual market clearing prices, which pacing commitments were kept, and which formats over-delivered or fell short. This is verified performance, agreed by both parties and written to a record neither can revise.
For buyers, that distinction matters enormously. A buyer agent with access to verified deal history knows which publishers have actually delivered video at £9 CPM in the UK market, not which publishers claim they can. It knows which flight structures produced consistent pacing, which creative formats generated the CPM outcomes that justified the spend, and which deal terms led to clean settlement versus costly renegotiation. It negotiates the next deal from a position of verified knowledge rather than accumulated assumption.
For sellers, the intelligence runs in the opposite direction. A publisher agent with verified settlement history knows which buyer archetypes pay within 2% of asking price, which budget structures lead to over-delivery risk, and which deal compositions produce mutual satisfaction versus dispute. Pricing to verified performance is categorically different from pricing to claimed capability.
This is the compounding advantage that bilateral architecture cannot offer. In Scenario B, every historical record contains some unknown quantum of drift. Agents that try to learn from this history are building market models on unstable ground: the more transactions they process, the more contaminated their reference data becomes. In Scenario C, every historical record is a verified fact. Agents that learn from this history build increasingly accurate market models. The learning compounds rather than decays.
Shared State enables a clean data substrate from which the next generation of media buying intelligence will be built, intelligence that benefits both sides of every transaction, compounds with every verified deal, and widens the performance gap between markets that have it and markets that don’t.
This new data layer is the substrate. Once both parties write to the same record, the intelligence that emerges from that record is a product question, and one the market is well-positioned to answer.
9. Implementation: The Minimum Viable Change
A Deal Sheet is created at the moment of negotiation, capturing the agreed CPM, impression target, flight dates, format, and targeting parameters in a single shared record. Both buyer and seller agents sign the record at execution. Throughout the campaign, pacing signals, delivery updates, and any amendments are written to the same record by both parties. At settlement, the deal sheet is the invoice with no reconciliation required.
Technology-Agnostic
Alkimi has made its own architectural choices after evaluating the available implementation approaches. Those choices, and the technical specification for integration, are available to qualified partners as part of a structured pilot engagement. The structural finding of this paper holds regardless of implementation: the value is in the shared deal sheet.
Cost Comparison
| Scenario B | Scenario B+ | Scenario C (Sim) | |
|---|---|---|---|
| Settlement infrastructure | $0 | $0 | $0 |
| Reconciliation labour | $0 | $298,218.75 / 90 days | $0 |
| Pacing interventions | 4,223 | 4,223 | 0 |
| Settlement gap (impressions) | 677,458,639 | 671,199,169 | 0 |
| Hidden tax | $47,777/day (derived from market-scale estimates; full calculation in Technical Appendix A3) | $47,777/day (derived from market-scale estimates; full calculation in Technical Appendix A3) + $3,314/day | $0 |
Scenario B+ deserves specific attention. B+ produced larger settlement gaps than B in two of three seeds in Simulation 1. The mechanism is counterintuitive but consistent: reconciliation interventions in a bilateral architecture require write operations to one or both databases to resolve a flagged discrepancy.
Each write operation is subject to the same ε drift as the original records; a correction based on a drifted record produces a new record that is drifted in a different direction. In two of three seeds, the accumulated effect of correction-induced drift exceeded the drift that would have accumulated without intervention. Adding reconciliation labour did not fix the problem. The B+ reconciliation cost of $298,218.75 over 90 days bought exactly one thing: a 0% formal reconciliation failure rate. Scenario B+ did not reduce dimensional divergence, eliminate pacing interventions, or close the settlement gap.
Data Sovereignty and the Right to Erasure
A shared settlement layer built on public blockchain infrastructure raises a legitimate compliance question: if deal records are written to an immutable ledger, how does the architecture accommodate GDPR Article 17 (right to erasure) or equivalent data protection obligations in other jurisdictions?
The architecture this paper describes provides a compliant mechanism through the separation of data storage and data provenance. Deal content, the actual terms, CPM, impression targets, targeting parameters – is stored as an encrypted blob with a configurable expiry period. The on-chain record contains only a cryptographic signature of that blob: a hash that proves the blob existed and has not been tampered with, but contains no personal or commercially sensitive data in itself.
When a blob is subject to a deletion obligation, it is removed from the decentralised storage layer. The on-chain signature remains, it is immutable, but it now points to a deleted object. The result is a tombstone record: cryptographic proof that a record existed and was deleted, with no recoverable content. This satisfies the “right to be forgotten” obligation while preserving the audit trail that regulators and counterparties may separately require. Jurisdiction-specific data residency requirements can be addressed through permissioned access controls on the decentralised storage layer.
Relationship to Existing Deal Identifier Infrastructure
In PMP and programmatic guaranteed environments, deal IDs already provide a shared reference point between buyer and seller. Deal Sheets described in this paper is not a replacement for deal ID infrastructure, it is the substrate that makes deal IDs useful throughout a campaign’s lifecycle, not just at the point of activation.
A deal ID confirms that both parties are transacting against the same inventory package. It does not record what was agreed on CPM, impression volume, pacing schedule, or flight dates at the moment of negotiation. It does not capture amendments made during the flight or a version history that an agent can reference when making optimisation decisions on day 57 of a 90-day campaign.
A shared Deal Sheet is complementary to deal ID infrastructure: the deal ID identifies the inventory relationship; the shared record captures everything agreed about how that inventory will be bought, at what price, on what terms, and how those terms evolved. For agentic buyers building optimisation strategies from historical campaign data, the difference between a deal ID and a verified deal record is the difference between knowing that a campaign ran and knowing what happened in it.
10. A Note On Confidence Levels
The limitations governing these findings are detailed in Section 3.5. Readers reviewing the results should hold three findings with the highest confidence: the zero-gap outcome in Scenario C (this is a structural property of shared record-keeping, not a statistical result), the 4,223 vs. 0 pacing intervention comparison (this is a direct count, not an estimate), and the failure taxonomy in Section 4 (the distinction between architecture-driven failures and model hallucinations is categorical, not continuous).
The findings that carry more uncertainty are the market-scale extrapolations in Section 9 (the hidden tax figure and the reconciliation labour cost), the temporal dynamics beyond 90 days, and the generalisability to heterogeneous multi-model agent markets. These are indicators of direction and magnitude, not precise predictions.
The simulation codebase, full transcript dataset (~90,000 negotiations), and parameter documentation are available to qualified reviewers.
11. Conclusion: The Market That Becomes Possible
The agentic advertising transition is happening. Anthropic’s Project Deal demonstrated that agents can negotiate with genuine sophistication. The agents are coming and many are already here.
AI agents will negotiate advertising deals. The question is what kind of market those agents operate in.
By day 10, agents were negotiating against contaminated history. By day 57, 812 decisions had been made on data that was wrong from day one. By day 90, 677 million impressions had no agreed record. The market degraded, gradually, invisibly, in ways no dashboard was watching.
This is what happens when agents store their own version of events and do not share state. The agents are good, protocols are well-designed. An accurate, verifiable data substrate is missing.
An agentic advertising market without a shared Deal Sheet is a negotiation engine or point to point solution. Agents can close deals but will not become a market without the one layer that is still missing.
Alkimi Exchange Research | Simulation codebase and methodology documentation available upon request: [email protected]